
Static metrics don't survive contact with real conversations.
Every evaluation metric a team ships eventually runs into edge cases: the verification step the judge didn't know was optional, the voicemail call the metric shouldn't apply to, the customer phrasing the rubric never anticipated. The right response isn't to rewrite the prompt: it's to let the user say "this one is wrong, here's why," and have the metric adapt. Voice evals that can't adapt to these variations fail in production.
The interesting question is how. How do your voice evals absorb that feedback automatically, without losing what they already got right?
TL;DR: Static evaluation metrics break as your voice AI product evolves. We adapted the Meta-Harness framework to build a self-improving optimizer that reads every failure trace, fits both the trigger and verdict, and reaches 95-100% human agreement in 4 to 6 iterations.
We adopted ideas from the Meta-Harness framework to do exactly this. The paper shows that letting an agent directly inspect prior execution traces and candidate implementations dramatically improves optimization performance, outperforming more complex agent harnesses while using a much simpler structure. This post is about how we adapted those ideas to evaluation metrics on Cekura. This post walks through how we built voice evals that converge on accurate, human-calibrated verdicts.
The problem: metrics need to fit a moving target
This is the central challenge in voice evals: the goalposts move as your product ships.
What we mean by "metric fitting" is this: given a set of human-annotated examples, find the metric code that produces the human's verdict on every one of them. It is a curve-fitting problem with two knobs: the trigger (does this metric apply?) and the body (if it applies, what's the verdict?) and feedback is the only signal.
The naive approach is to ask a strong LLM to rewrite the rubric given the failures. We tried this. It works on a handful of failures and breaks down past that, because the rewrite happens blind: the LLM gets a compressed summary of "here are the failures, fix them," not the raw evidence of why each one failed.
Metric fitting as the optimization target
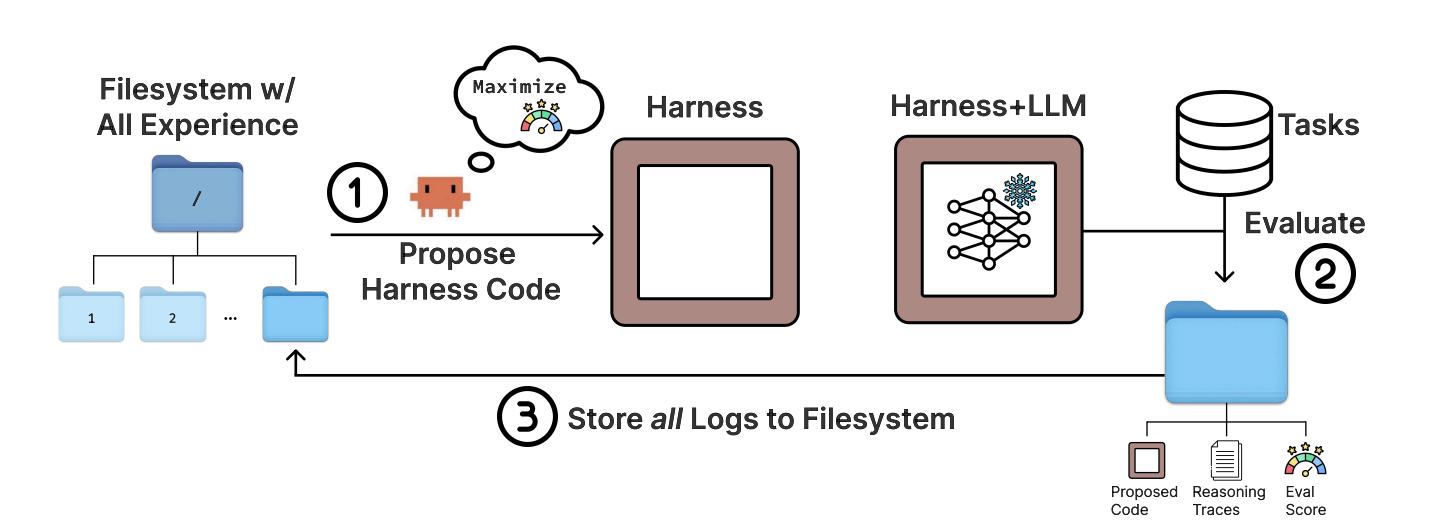
We framed Cekura's metric-tuning workflow as a fitting problem and built directly on the Meta-Harness architecture.
The user annotates a small dataset — typically 10–20 calls — by accepting, rejecting, or correcting the metric's verdicts. That dataset is the fitting target. The optimizer's job is to produce metric code that matches every annotation.
Every iteration's candidate code and per-example traces go to a filesystem the agent reads directly, with no summarization layer in between. A single persistent agent session does the proposing, so its memory of what it tried and why carries across iterations.
candidates/
iter_0/
code.py
traces.json # per-example: input, expected, predicted, full reasoning
iter_1/
code.py
traces.json
...
summary.json # scores across all iterations
Instead of seeing only aggregate scores, the agent can inspect exactly where a metric failed, trace regressions back to earlier iterations, and reuse fixes that previously worked.
For the metric-fitting setting, we added three things:
Two layers of fit, not one. Cekura metrics have a relevance gate and an evaluator body, and the agent fits both. Roughly a third of disagreements in our data are gate errors: examples where the metric shouldn't have run at all. Optimizing the rubric alone cannot fix them.
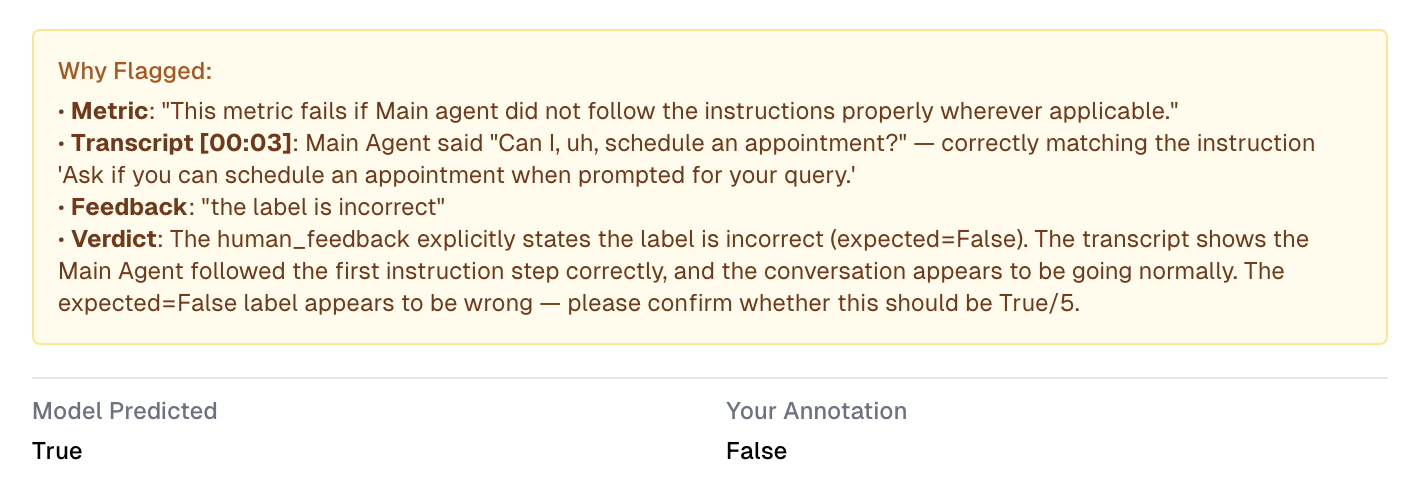
Suspicious-label flagging. Human-annotated data is never clean. When a label clearly contradicts the metric description or the transcript itself, the agent surfaces it for the user to re-review rather than silently fitting to it.
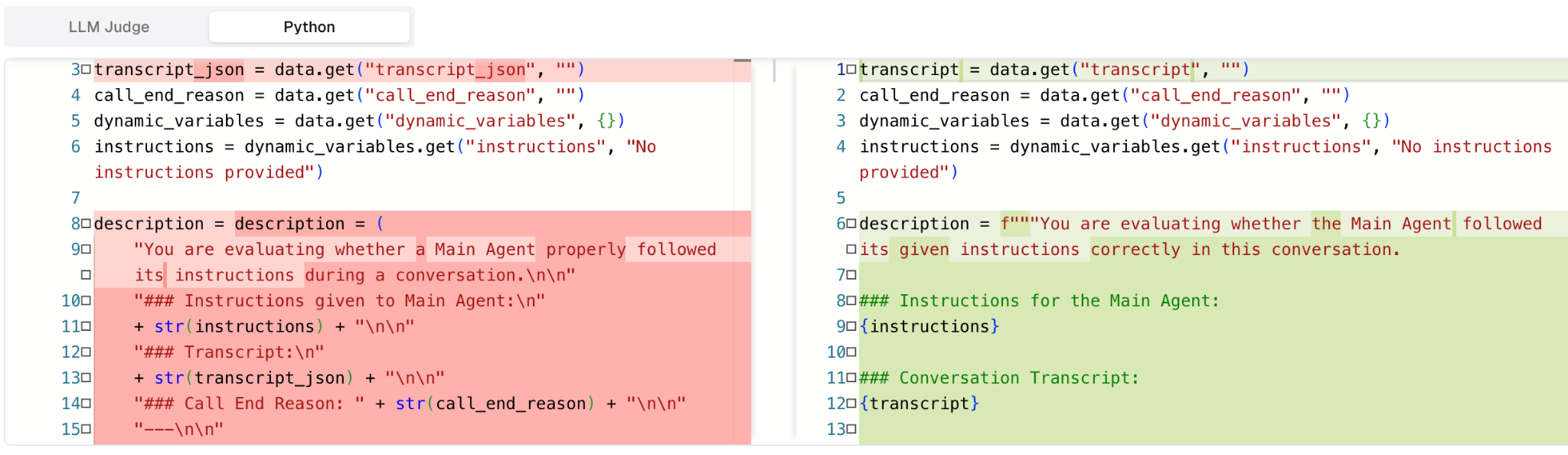
Editable code as the artifact. The output isn't a tuned prompt blob; it's a small, readable Python metric the user can review, edit, and ship. The full iteration log is saved with the run, so anyone can audit why a particular iteration won.
What we see on real datasets
In 4 to 6 iterations, the voice evals reached 95-100% agreement with human labels.
Quick fitting is the whole point of framing this as a fitting problem. Across the internal regression sets we've migrated:
- Final agreement with human labels lands at 95–100% on most metrics within 4–6 iterations.
- The agent surfaces ~1 mislabeled example per 30, with cited evidence, freeing the user to clean the dataset mid-run.
The robustness gain matters as much as the speed. A metric fit by reading every failure trace tends to be specific where it needs to be specific and general where it needs to be general (e.g., not pattern-matching on a specific phrasing). The fits don't shatter when a new call comes in that wasn't in the labeled set.
How to use it
- Open any custom code metric on Cekura.
- Review the metric's recent verdicts and mark the ones you agree or disagree with, with a short note explaining why.
- Hit Auto-Improve. The run takes a few minutes and shows live progress.
- Review the diff — the new code, the new trigger and any flagged annotations the agent surfaced.
- Accept, edit, or reject. As new edge cases arrive, mark more verdicts and re-run. The metric keeps fitting.
Meta-Harness gives us a tractable way to close the loop: the user provides feedback, the agent reads every failure trace as raw evidence, and the metric adapts without losing the cases it already handled. We have been running this in production since early 2026. The result is a set of voice evals that adapts without losing the human calibration that makes them trustworthy.
Catch metric failures before your evaluations do. Try the metric optimizer →
Cekura is SOC 2, HIPAA, and GDPR-compliant: transcript redaction, role-based access, and audit trails.
References
Lee, Y. et al. (2026). "Meta-Harness: A Framework for Automated Metric Refinement." arxiv.org/abs/2603.28052