Test, Monitor and Self Improve Voice & Chat AI Agents
Launch in minutes, not weeks. Run voice evals before going live, then monitor real production calls and continuously improve with Cekura's intelligent feedback.






Simple. Seamless. Smart.
Tired of calling agents?Automate it today.

Integrates directly with









How Cekura Works
simulate scenarios
Start Call: Greet Customer
Outbound Call
You are calling a customer back about a problem they were having with one of our products.
Your new prompt broke appointment cancellation?
Quickly test how prompt changes impact core user flows like cancellations, reschedules, or follow-ups.
Personalities
Female, American Accent, Professional
Male, British Accent, Professional
Female, Indian Accent, Pleasant
Male, German Accent, Angry
An impatient, interruptive user causing issues?
Test how your agent handles interrupts and off-script users.
Replay Real Conversations
An old conversation that always causes issues?
Replay known trouble spots to prevent recurring failures.
Voice Evals
Skipping compliance checks suddenly?
Test key flows for missing disclaimers or checks — catch issues before they go live.
Voice Observability

Detect voice quality issues
Purpose-built signals for voice: gibberish detection, interruption tracking, latency, sentiment, pitch - running on every call automatically.
Stereo recordingsReal-time10+ metrics
Optimize LLM Judges
Tune evaluation prompts against real call recordings in Labs. Edit, replay, score - until your judges match ground truth.
Auto ImprovePrompt evalCustom Code
Track production metrics
Build custom plot layouts - duration trends, sentiment, drop-off, success rates. Filter by agent or date.
Add PlotLive Refresh

Real-time Alerting
Instant notifications for errors, failures, and performance drops. Configure thresholds and get alerted via Slack, email, or webhooks.
Custom RulesMulti-channelInstant
Conversation Analytics
Deep dive into conversation patterns, user behavior, and interaction flow. Identify bottlenecks and optimize your agent's performance.
Flow AnalysisUser Insights

Works for everyone
Test any workflow with various personalities and evaluate based on your needs
Trusted by 70+ Conversational AI companies across the globe
Shipping a Self-Improving Voice Agent to Customers: The Product and the Playbook
Closing the eval loop was the algorithm. Here's the product and the POC playbook that made customers willing to run it on their own production voice agents.

Lavish Gulati
Wed Jul 29 2026
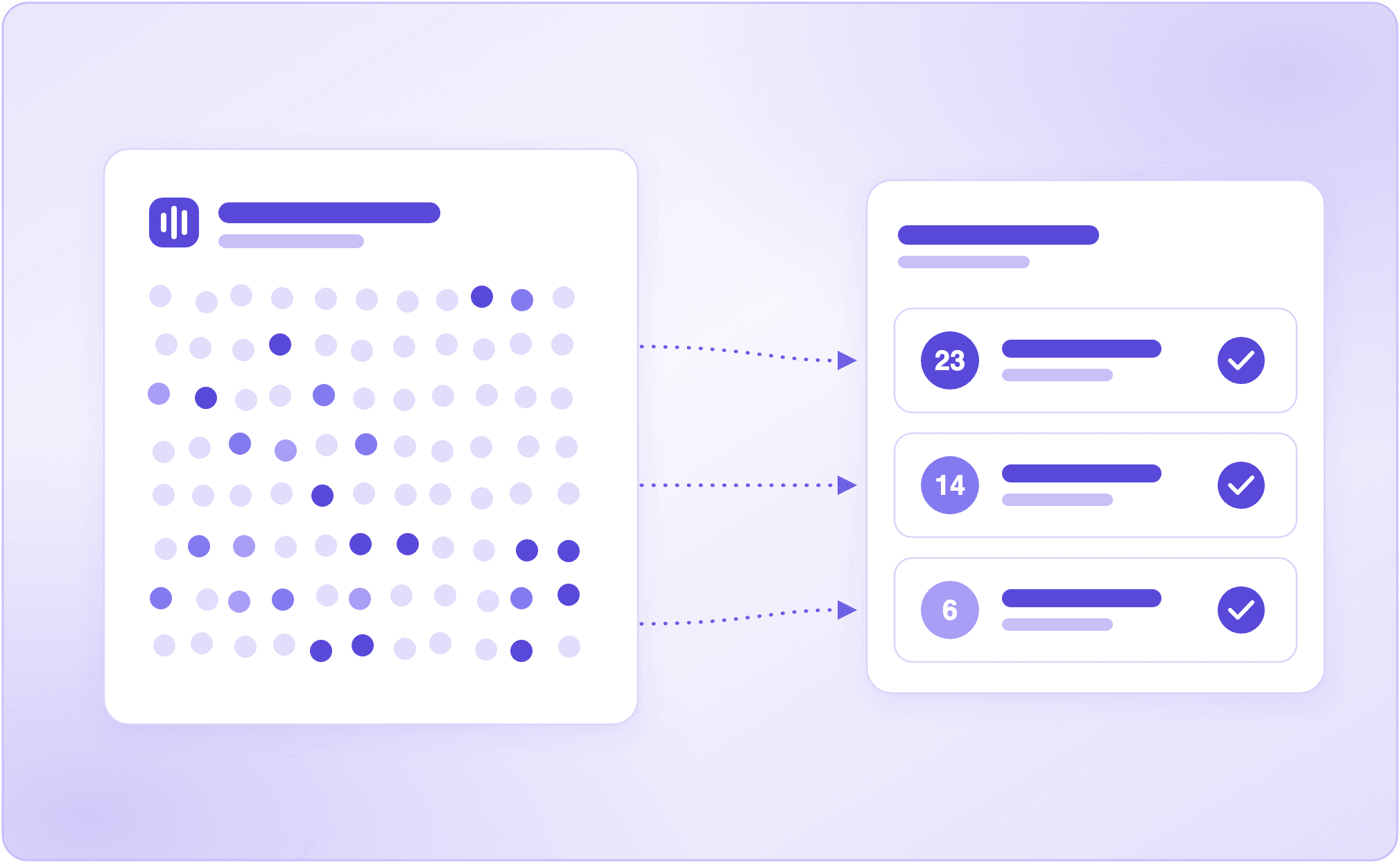
Call Analytics for Voice Agents: Turn Thousands of Failing Calls Into a Handful of Fixes
Call analytics for voice agents should tell you why calls fail, not just how many. See how Cekura Insights clusters failing calls into a few root-cause fixes.

Satvik Dixit
Tue Jul 07 2026

Voice AI Simulation: What It Takes to Get It Right
Voice AI simulation is what makes agent testing reliable. See how Cekura builds realistic testing agents, and the accuracy and latency tradeoffs that matter.

Rishabh Sanjay
Tue Jul 07 2026