
Think about the last time you talked to a voice assistant or an AI phone agent. If the interaction felt awkward, it probably wasn't because of the agent's vocabulary. It was endpointing, the timing of the conversational handoff. Something much subtler, quieter, and deeply human.
Did it wait a beat too long before answering? Did it awkwardly jump in and cut you off before you finished your thought?
In a human conversation, we hand the microphone back and forth without a second thought. We read tiny implicit cues (a slight drop in pitch, a brief pause, the grammatical shape of a finished sentence) and we simply know when it's our turn to speak. For a machine, that handoff is one of the absolute hardest engineering problems in voice AI.
Most monitoring tools will tell you if your agent stayed online or if its API responded quickly. What they rarely tell you is whether the agent took its turn at the right exact moment. That behavioral gap is what separates a fluid, human-like voice agent from a deeply frustrating robot.
In this post we break down the mechanics of endpointing and turn detection, and look at how teams build, tune, and test them at scale.
What Do Endpointing and Turn Detection Actually Mean?
These two terms are frequently tossed around interchangeably, but they solve different layers of the conversation problem.
| Concept | What It Means | In Plain English |
|---|---|---|
| Turn Detection | The broad management of conversational flow and state. | "Whose turn is it to speak right now?" |
| Endpointing | The specific, load-bearing decision engine inside turn detection. | "Did the user just finish their sentence, or are they just taking a breath?" |
Think of turn detection as the entire dance. It handles when the user is talking, when the agent should start, and what to do when both parties talk over each other (interruption handling). Endpointing is the critical trigger step within that dance: the exact millisecond the agent decides, "They have stopped, I can respond now."
Get endpointing right, and the conversation flows like water. Get it wrong, and everything downstream breaks down.
The Endpointing Goldilocks Problem: Too Eager vs Too Patient
Endpointing is a delicate balancing act with two brutal failure modes:
Failure Mode 1: The Interrupter (Premature Endpointing)
The agent treats a natural mid-sentence pause as the end of your turn and barges in. You say: "I'd like to book a flight to..." You pause for a half-second to check your calendar, and the agent instantly cuts in: "Where would you like to fly to?" It's jarring and robotic.
Failure Mode 2: The Laggy Robot (Late Endpointing)
Terrified of interrupting, the agent waits around to be absolutely certain you're done. This caution manifests as dead air. A pause of even 400 milliseconds after you stop talking starts to feel laggy on a phone call. A full second of silence feels completely broken.
What makes the middle ground so narrow is the chaotic reality of human speech. Real people don't speak in perfect audio packets. They pause to think, say "umm," trail off, cough, talk over background traffic noise, or call from spotty cellular connections. A naive rule like "wait for 800ms of silence" falls apart the moment someone pauses mid-thought in a noisy cafe.
How Modern Voice Agents Handle Endpointing: 3 Signals That Trigger a Turn
To survive the real world, modern voice agents can't rely on a single clue. The best architectures combine three independent signals to make a decision:
1. Acoustic Silence via Voice Activity Detection (VAD)
A small, lightning-fast model listens to the raw audio stream and flags whether speech is present. A widely used open-source standard here is Silero VAD. Think of it as the agent's ears: dozens of times per second, it answers a binary question: Is someone making human speech sounds right now?
VAD is excellent at noticing when sound has stopped, but silence alone is ambiguous. A breath between two clauses looks identical to the end of a sentence to a pure acoustic model.
2. Lexical Context via the Transcript
While the VAD listens to the audio, the Speech-to-Text (STT) system (like Deepgram) is busy turning that audio into text. It signals when it has a finalized, confident transcript. A complete, punctuated clause is incredibly strong evidence that a thought is actually finished.
3. Semantic Endpointing
Increasingly, advanced setups add a third, smarter signal: semantic endpointing (or "smart turn detection"). Here, a language model judges whether the sentence sounds complete based on its grammatical meaning and intonation.
"I want to transfer..." sounds unfinished, even if followed by a long pause.
"I want to transfer three hundred dollars." sounds completely done.
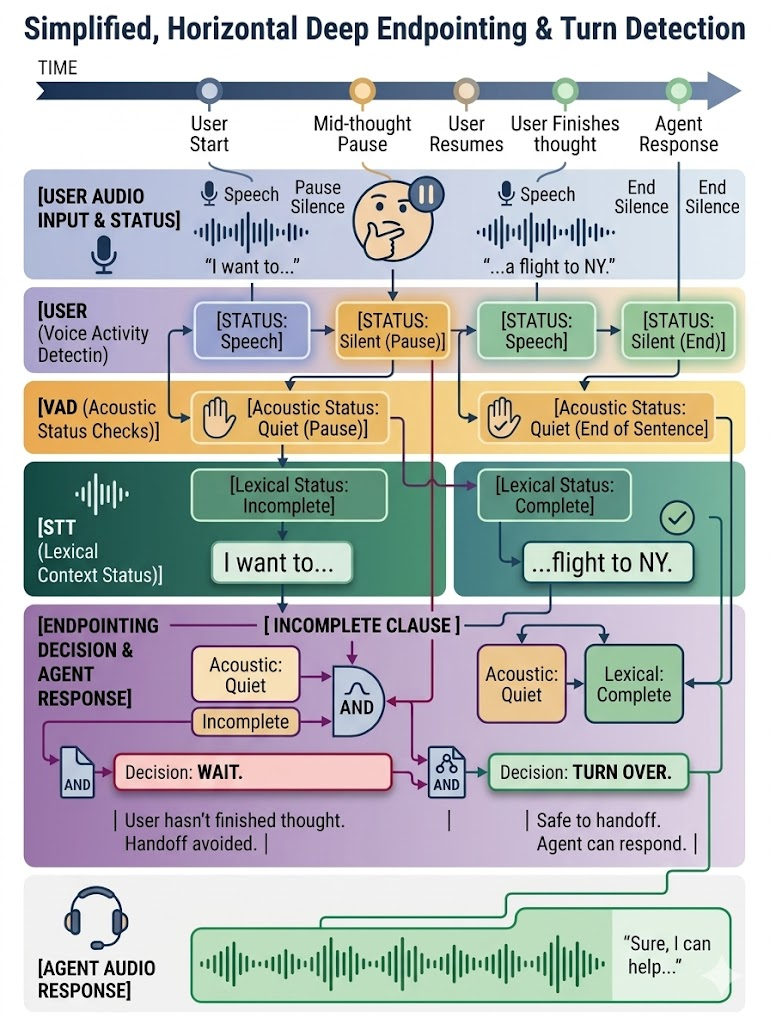
The Conversational Flow Lifecycle
The diagram below maps out how these multi-signal inputs intersect to handle both a deceptive mid-sentence pause and a true finalized sentence handoff.
Our Playbook: Cekura
Our own voice agents are built on Pipecat, the open-source framework for real-time voice. We leverage their Silero VAD integration for our core acoustic layer, and then layer our own custom turn-detection logic on top. We force the agent to wait for a dual trigger: the audio must go quiet and the STT engine must deliver a finalized transcript.
When building this out, we ran into two highly practical engineering challenges that you will likely face too:
The Slow-Transcript Problem: STT services sometimes detect that you've stopped speaking but take an extra moment to process and deliver the final, punctuated transcript. If your agent just sits there waiting for the final packet, you introduce artificial latency (dead air). To solve this, if the audio has been dead quiet for a specific threshold but the final transcript is slightly lagging, our agent can choose to speculative-predict on the stable, unfinalized text it already has. This recovers precious milliseconds without sacrificing accuracy.
Tunability is Mandatory: A patient healthcare intake line for elderly patients requires a completely different conversational rhythm than a snappy, drive-through food ordering bot. How long the agent waits, and how easily it can be interrupted, must be highly configurable parameters per scenario, never hardcoded into your core engine.
The Harder Half: Proving It Works at Scale
Building a nice turn-detection loop on your local machine is one thing. Knowing whether it actually works across 10,000 messy, live production calls is a completely different beast. Turn-taking failures are intermittent, environmental, and incredibly easy to miss if you're just looking at basic text logs.
This exact challenge is why we built Cekura. To measure turn-taking and endpointing quality with engineering precision, we record every single call in stereo. User audio is isolated entirely on the left channel and agent audio on the right channel. We run high-accuracy VAD on each channel independently post-call.
By analyzing the overlapping or isolated audio frames, we extract objective, core metrics:
Response Latency (p50, p95, p99): How many milliseconds pass between the user stopping their speech and the agent starting theirs? We track this via percentiles because an average latency of 400ms sounds great, but if your p99 is 2.5 seconds, 1% of your customers are experiencing an agonizing, broken conversation.
Interruptions and Talk-Over: Did the agent start speaking while the user's channel was still active? Our overlap detection flags these moments instantly, and we use a loudness filter to weed out false positives (like a user coughing or background noise being misidentified as an interruption).
Premature vs. Late Endpointing: By correlating the audio overlaps with the text transcripts, we can automatically categorize why a turn failed. Was the agent cutting people off mid-sentence, or leaving them hanging?
Engineering Dependability: Testing Responsively and Reliably on Cekura
How do you transition from guessing if your endpointing works to proving it works before hitting production? Relying on live human QA testers is a bottleneck; they can't accurately measure a 300ms latency drift or reproduce a specific background noise profile reliably.
At Cekura, we re-engineered the testing stack to make voice evaluation deterministic, repeatable, and deeply resilient. Here is exactly how we make testing reliable:
1. Automated Behavioral Simulation (The "Messy Caller" Suite)
We don't just send flat audio files into your agent. Cekura synthesizes real-time conversational agents designed to act like real, unpredictable humans. Our testing suite injects behavioral edge cases directly into the call stream:
The Cognitive Pauser: Programmed to pause for exactly 600ms mid-sentence to look up an account number.
The Mumbler & Filler Speaker: Injects frequent "umms", "ahs", and throat clears to verify that your VAD doesn't mistake a vocal filler for a finished sentence.
The Background Noise Profiler: Layers acoustic coffee-shop chatter, honking horns, or cellular packet loss over the speaker's voice to ensure your VAD thresholds don't drop text packets or misinterpret environmental noise as a human voice.
2. CI/CD Regression Testing for Voice Prompts and Models
A common trap teams fall into is updating their LLM system prompt to be "friendlier," only to realize weeks later that the new model architecture outputs text slightly slower, causing a catastrophic spike in late endpointing.
Cekura treats voice quality like software code. Every time you change a prompt, tweak an architectural parameter, or swap an LLM provider, Cekura automatically triggers a regression test across your historical call profiles. If your p95 response latency degrades by even 50 milliseconds, your build fails in staging, long before an angry customer experiences it.
3. Audio-Level Timestamps vs. Transcript Collapse
Many teams try to measure latency by looking at the timestamps returned by their STT transcriptions or LLM completion logs. This is a critical mistake. Under heavy network stress or conversational interruptions, live transcripts frequently collapse, drop trailing words, or miscalculate internal timestamps.
Cekura bypasses application-level metadata entirely. Because we evaluate the raw, dual-channel stereo audio at the frame layer, our latency tracking is accurate down to the individual millisecond. We know exactly when the sound waves hit the wire and when your agent reacted, giving you an immutable source of truth.
Where Cekura Fits in Your Stack
Your voice infrastructure (Vapi, Retell, LiveKit, Pipecat) runs the execution of your agent. Cekura is the testing, evaluation, and monitoring layer that ensures it actually behaves like a human.
We plug seamlessly into the tools you already use. And because voice data is highly sensitive, Cekura is built from the ground up to be SOC 2, HIPAA, and GDPR compliant, complete with automatic transcript redaction and robust audit trails.
Don't rely on acoustic silence alone. Build your agent on a multi-signal approach, make your timing parameters highly tunable, and stop guessing and measure your conversational latency objectively.
If you're shipping a voice agent and want to ensure it handles the handoff like a human, explore our guide to voice agent testing or book a demo with our engineering team today.