
What's the best voice AI API for real-time audio processing? It's a more complicated question than most developers expect. I tested the leading platforms across latency, integration depth, and real deployments to find out what actually holds up.
7 Best Voice AI APIs for Real-Time Audio Processing: Quick Comparison
Pricing models range widely across these platforms. Some charge per token, others per minute, and one uses a flat hourly rate. The difference here alone can change your monthly infrastructure bill by 4x at production scale.
What Is the Best Voice AI API for Real-Time Audio Processing?
The best voice AI API for real-time audio processing depends on where you're building in the stack.
Full-stack pipelines favour OpenAI or Inworld, STT-first builds lean toward Deepgram or AssemblyAI, and teams that want component-level control with at-cost provider pricing should look at Vapi. See the full ranking below.
Here's a quick overview of the platforms I tested:
| 🖥️ Tool | 💰 Starting Price | ⚡ Strengths | 🎯 Best For |
|---|---|---|---|
| OpenAI Realtime API | $32/1M audio input tokens | Native S2S, MCP + SIP support | Accuracy-critical voice agents |
| Inworld Realtime API | $35/1M chars, On-Demand | #1 TTS quality (ELO 1,236), full-stack, dual transport | Full-stack real-time pipelines |
| Deepgram | $0.0048/minute, Nova-3 Pay as you go | Sub-300ms STT, 6.84% WER, multiple languages | STT-first pipelines |
| ElevenLabs Conversational AI | $0.08/minute, ElevenAgents Starter | TTS #2 ELO, 70+ languages, 380+ voices, 75ms latency | Voice quality-first agents |
| AssemblyAI Voice Agent API | $4.50/hour flat, Voice Agent API | Flat-rate full pipeline, #1 ASR on HuggingFace, ~1s latency | Phone-call deployments |
| Vapi | $0.05/minute + provider costs | Multi-LLM/STT/TTS routing, p50 <500ms, BYOK support | Flexible multi-provider orchestration |
| Retell AI | $0.07/minute Pay as you go | All-in pricing, built-in telephony, turn-taking | No-code voice agent setup |
How I Researched and Tested These Voice AI APIs
I evaluated each API against production conditions. I ran three scenarios: a customer support agent handling mid-sentence interruptions over a noisy phone line, an outbound sales call with rapid back-to-back turns, and a multilingual assistant switching between English and Spanish mid-conversation.
Each API ran at least 10 calls during peak hours over a mobile connection to expose latency spikes that only appear under real network conditions.
Here's what I tested:
- Latency: Human conversation runs on tight timing. Turn gaps average just 200ms. Any API that consistently misses that window erodes user trust before the conversation ends.
- STT accuracy: I tested against noisy and accented audio, which is closer to real production conditions. Production systems fail on interruptions, overlapping speech, and code-switching. WER on curated datasets only gets you so far.
- Integration depth: I measured how easily each API plugs into the rest of a typical stack and how much custom code each integration requires.
- Pricing at scale: What you actually pay per minute or per character at production volumes, including provider add-ons where relevant.
- Use cases: How each tool holds up across phone-based deployments, browser-native agents, and hybrid stacks with swappable STT/TTS layers.
This hands-on approach gave me a clear read on which APIs hold up when conditions get messy.
1. OpenAI Realtime API: Best for Accuracy-Critical Voice Agents
What it does: Native speech-to-speech API that processes audio end-to-end in a unified pipeline. It covers speech recognition, reasoning, and voice synthesis.
Best for: Development teams already in the OpenAI ecosystem that need reliable tool-calling during live voice sessions.
GPT-Realtime-2, released in May 2026, is OpenAI's first voice model built on GPT-5-class reasoning. It ships GA with a 128K context window, MCP support, image input, and SIP, covering more ground than most single-model APIs.
On OpenAI's internal benchmarks, it scores 96.2% on Big Bench Audio reasoning, up from 81.4% on the previous model.
Key Features
- Response preambles: The model says "Let me check that" while executing tool calls, to reduce dead air during longer tool-calling sequences.
- Parallel tool calls: Runs multiple back-end requests simultaneously and narrates which one is in flight.
- WebRTC, WebSocket, and SIP transports: WebRTC for browser-native apps, WebSocket for server-side orchestration, SIP for telephony. All share the same event schema.
Pros and Cons
Pros:
✅ GPT-5-class reasoning runs natively in the audio stream, with no intermediate text conversion
✅ 128K context window handles long voice sessions without external memory scaffolding in most cases
✅ MCP and SIP support built in, so standard enterprise telephony setups typically work without additional middleware
Cons:
❌ Audio pricing at $32/1M input tokens and $64/1M output tokens compounds quickly at B2C volumes
❌ Locked to OpenAI models, with no option to swap in third-party STT, TTS, or LLM providers
❌ No voice cloning or custom voices
What Users Say

"Worked great. super fast. What context is loaded? Something as simple as Wikipedia entries for any given park or ...." — Verified User, Reddit
"I tried the demo, but it seems like the assistant responded in text, and then after the text generation was done, it started reading the text out loud." — Verified User, Reddit
Pricing
Per openai.com/api/pricing, GPT-Realtime-2 starts at $32.00/1M audio input tokens and $64.00/1M audio output. GPT-Realtime-Whisper (transcription only) runs $0.017/min. It's fully pay-as-you-go with no subscription required.
Bottom Line
This one's great if you're already in OpenAI's ecosystem and need a highly capable reasoning model in a voice pipeline. Limits currently show up around provider flexibility and strong non-English coverage at scale.
2. Inworld Realtime API: Best for Full-Stack Real-Time Pipelines
What it does: Full-stack speech-to-speech API that handles STT, LLM inference, TTS, VAD, and turn-taking in a single endpoint.
Best for: Teams that want a single API to handle the full real-time voice pipeline.
Inworld's Realtime API runs the full pipeline through one endpoint, following the OpenAI Realtime event schema, so teams already on that stack can migrate with little rework. On latency, P90 time-to-first-audio sits under 250ms on TTS 1.5 Max and under 130ms on TTS 1.5 Mini.
Key Features
- Inworld Router with 220+ LLM models: Swap STT, LLM, or TTS at the API level without touching client code or redeploying per variant. A/B testing for voice models and VAD settings happens inside the router.
- Semantic VAD with barge-in support: Turn detection reads the meaning of the transcript to decide when to respond, applying semantic understanding to reduce premature cutoffs. Setting interrupt_response: true stops the agent mid-sentence and picks up the new input on the spot.
- Dual transport on the same event schema: WebRTC and WebSocket share identical events, so hybrid architectures (WebRTC on the client, WebSocket on the backend) run on one codebase.
Pros and Cons
Pros:
✅ STT, LLM, TTS, VAD, and interruption handling are all managed by Inworld, with minimal glue code between stages
✅ GDPR and SOC 2 Type II on all paid plans, with HIPAA and Zero Data Retention available as add-ons on Growth
✅ EU and India data residency available on Enterprise, relevant for regulated industries
Cons:
❌ TTS 1.5 covers only 15 languages. If you have broad multilingual needs, you'll want to verify coverage per model before committing
❌ Professional voice cloning only available from Growth plan ($1,500/mo) upward
❌ Realtime API is currently in research preview, with a less established production track record than OpenAI's GA release
What Users Say

"I'm most excited about the improvements made in cross-lingual. It's so seamless to have an engaging conversation and switch between multiple languages like English, Hindi, then French, and it's the same voice." — Nikki, Product Hunt

"It sounds too much like an audiobook narration. I guess it was trained on that input?" — Andre J., Product Hunt
Pricing
Per inworld.ai/pricing, Creator starts at $25/mo with TTS at $35/1M chars. Higher tiers (Developer at $300/mo, Growth at $1,500/mo) come with rate discounts of up to 20 and 40%, with HIPAA and ZDR add-ons on Growth. Enterprise is custom.
Bottom Line
Go with Inworld if you want production-grade, real-time voice managed through a single API. Teams with specific third-party LLM or STT requirements outside Inworld's current roster may find Vapi's component-level flexibility a closer match.
3. Deepgram: Best for STT-First Pipeline Stacks
What it does: Speech-to-text API built for real-time voice agents, offering streaming transcription, turn detection, and a full Voice Agent API for conversational AI.
Best for: Teams building custom voice pipelines that need high-accuracy transcription as the STT layer, particularly in contact centers and regulated healthcare environments.
Deepgram runs two STT models aimed at different jobs. Flux is built for conversational voice agents across 10 languages, with natural interruption handling and very low latency. Nova-3 targets high-accuracy production transcription with noise robustness.
Both deliver transcripts in under 300ms, which makes them a practical STT layer for stacks that combine third-party LLMs and TTS engines.
Key Features
- Flux model with built-in turn detection: It detects language automatically and knows when the user's turn ends.
- Keyterm Prompting: Boosts recognition of domain-specific vocabulary, product names, and acronyms with up to 90% higher keyword recall rate.
- Voice Agent API with BYO LLM and BYO TTS: Teams plug Deepgram's STT into their existing model stack, with concurrency capped at 45 sessions on Pay as you go and 60 on Growth. Enterprise required above that.
Pros and Cons
Pros:
✅ Under 300ms transcription latency for real-time voice agents
✅ Multi-language support on Nova-3, covering most global deployment requirements
✅ Covers HIPAA, SOC 2 Type I and II, GDPR, CCPA, and PCI from day one
Cons:
❌ Flux covers only 10 languages. If you're building conversational agents in other languages, you need Nova-3, which lacks native turn detection.
❌ TTS limited to Aura models with no voice cloning, custom voices, or emotional expressiveness controls on self-serve plans.
❌ Keyterm Prompting and Speaker Diarization are add-ons billed on top of base transcription rates.
What Users Say
"The best thing is an end-to-end voice agent. In a modular manner to select different choices of models for STT, LLM, TTS." — Sheel S., G2
"TTS language gap, pricing complexity, limited voice styles." — Jyotiraditya D., G2
Pricing
Nova-3 STT starts at $0.0048/min pay as you go. The Voice Agent API runs $0.075/min on Standard, dropping to $0.050/min with BYO LLM and BYO TTS. Growth plan ($4,000+/year) cuts rates by up to 20%.
Bottom Line
Deepgram makes the most sense when you need production-grade STT as a standalone layer, especially in regulated industries where HIPAA and PCI compliance matter from day one.
Inworld and ElevenLabs are worth evaluating when TTS quality and voice cloning are part of the scope.
4. ElevenLabs Conversational AI: Best for Voice Quality-First Agents
What it does: Conversational AI platform that delivers low-latency voice agents with emotionally expressive, natural-sounding TTS.
Best for: Teams that prioritize voice naturalness and emotional expressiveness, particularly where the agent's voice directly affects trust or conversion, like healthcare intake or premium customer support.
ElevenLabs Conversational AI runs transcription, language understanding, and synthesis together in one pipeline. It delivers sub-second responsiveness. Telephony connects via Twilio, Genesys, Vonage, Telnyx, Plivo, or any SIP-compatible PBX.
Key Features
- Instant Voice Cloning: Choose from expressive preset voices or clone a custom voice tailored to specific products, regions, or use cases.
- Emotional and contextual awareness: Adjusts tone and pacing to match customer sentiment in real time.
- Custom LLM support: Connect any LLM to the agent pipeline while retaining ElevenLabs' TTS and STT layers.
- Knowledge Base configuration: Upload docs or connect a data source, then define workflows and escalation paths without writing code.
Pros and Cons
Pros:
✅ 10,000+ voices across 70+ languages and a range of accents, the broadest voice library on this list
✅ Emotional and contextual adaptation in real time, which adapts to customer sentiment mid-call
✅ HIPAA-compliant via BAA on Enterprise, covering healthcare deployments
✅ Startup Grants Program: 12 months free plus 33M characters for qualifying startups
Cons:
❌ HIPAA BAA is only available on Enterprise, with custom pricing and no self-serve access
❌ Low-latency TTS at $0.05/minute, only available from Business plan ($990/mo) upward
❌ Telephony requires third-party integration via Twilio, Vonage, or SIP PBX, with no native phone number provisioning built in
What Users Say

"This is such a long-awaited feature! The potential to integrate low-latency, scalable voice agents into websites and apps is exciting! You guys are always killing it in the TTS space!" — Tony Tong, Product Hunt
"Just tested it out. IMO the voices sound a little too sterile and it removes an aspect of realism." — Bradley Young, Product Hunt
Pricing
Starter begins at $6/mo with 30k credits. Creator ($22/mo) adds Professional Voice Cloning. Low-latency TTS at $0.05/min is available from Business ($990/mo) upward. Enterprise is custom with BAA/HIPAA included.
Bottom Line
Pick ElevenLabs when voice quality is a direct business variable, particularly in healthcare intake, premium customer support, or any deployment where a flat-sounding voice erodes trust.
5. AssemblyAI: Best for Phone-Call Deployments
What it does: Streaming speech-to-text API with four specialized models for real-time transcription, built for voice agents, call centers, and clinical AI scribes.
Best for: Teams deploying voice agents in production environments where transcription accuracy on messy real-world audio is the primary requirement.
AssemblyAI's Universal-3 Pro Streaming is AssemblyAI's primary model for voice agents, delivering ~150ms P50 latency, finals-only output, and strong accuracy on proper nouns, numbers, and technical jargon.
It supports natural language prompting up to ~1,500 words and lets teams define transcription behavior in plain English. All streaming models support unlimited concurrency with no cap on parallel sessions, regardless of plan.
Key Features
- Natural language prompting: Define transcription behavior in plain English up to ~1,500 words. It's only available on Universal-3 Pro Streaming.
- Medical Mode add-on: Clinical-grade accuracy with medical terminology recognition and noise-resilient transcription on HIPAA-ready infrastructure.
- Whisper Streaming: Open-source Whisper enhanced with unlimited concurrency and HIPAA BAA, for long-tail language support at $0.30/hr.
Pros and Cons
Pros:
✅ Unlimited concurrency across streaming models, with no parallel session caps
✅ Universal-2 covers 99 languages at $0.15/hr, among the lowest prices per language on this list
✅ Medical Mode covers healthcare and clinical AI scribe use cases with HIPAA BAA available on request
Cons:
❌ Universal-3 Pro Streaming supports only 6 languages (EN, ES, FR, DE, IT, PT). Teams that need broader coverage will have to use Whisper Streaming, which lacks natural language prompting
❌ AssemblyAI is STT-only, with no TTS or LLM layer built in. Both need to come from separate providers
❌ ~150ms P50 latency is specific to Universal-3 Pro Streaming. Other models are not rated to the same benchmark
What Users Say
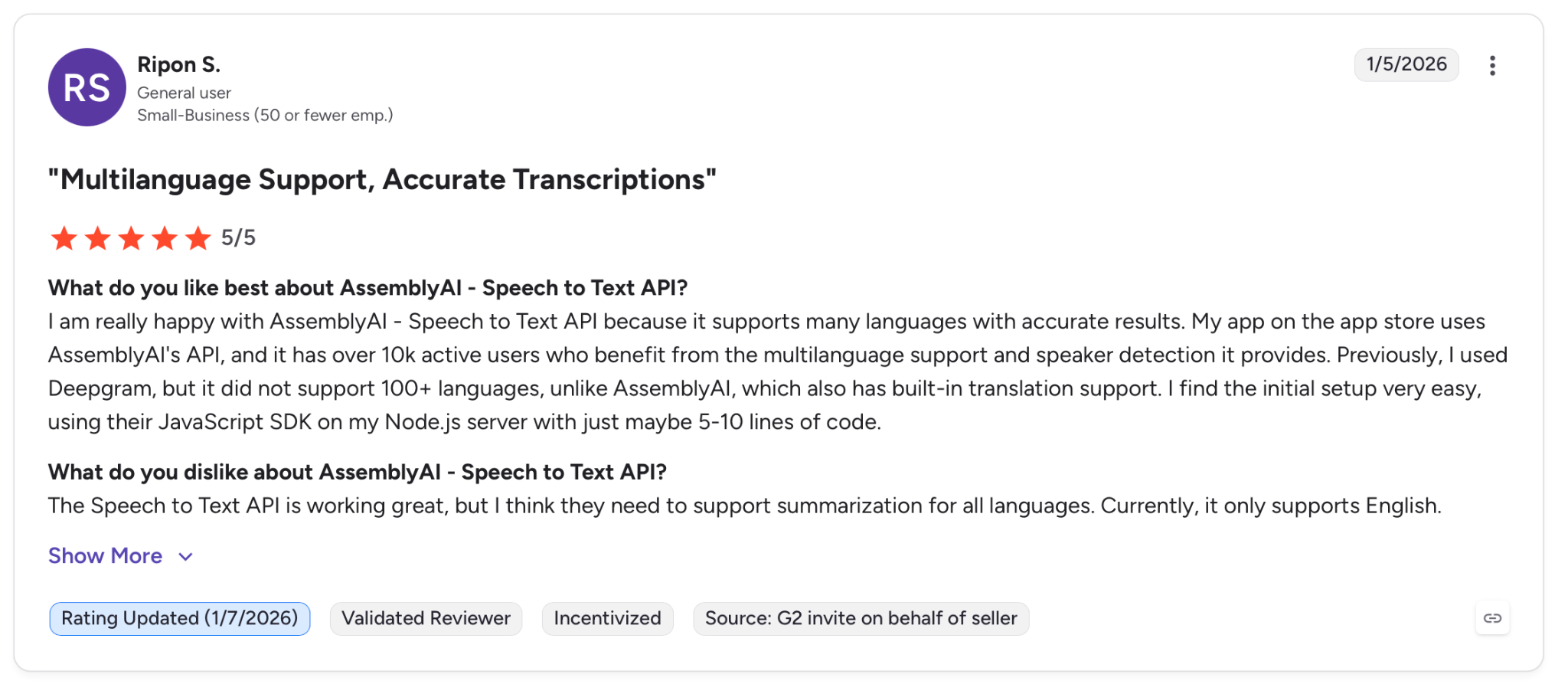
" I used Deepgram, but it did not support 100+ languages, unlike AssemblyAI, which also has built-in translation support." — Ripon S., G2
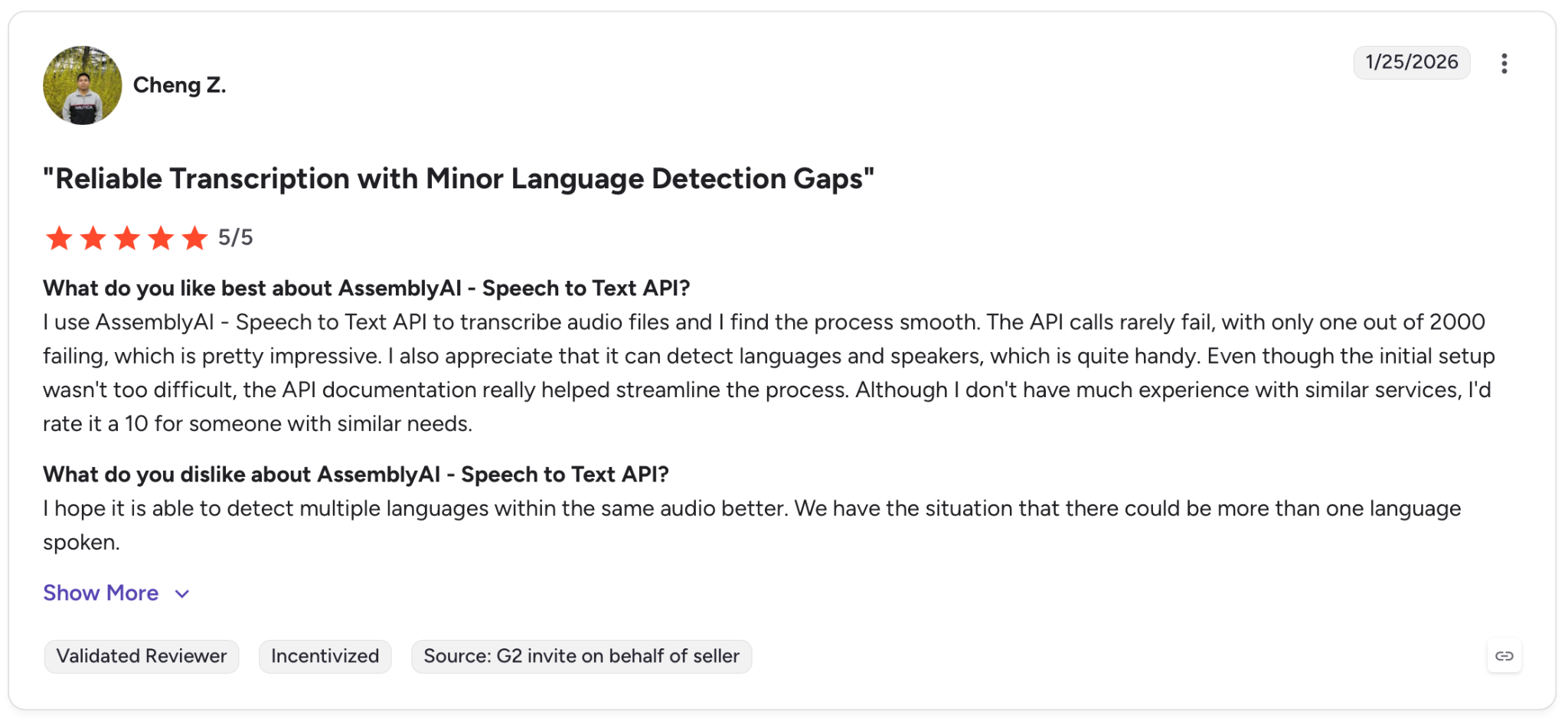
"I hope it is able to detect multiple languages within the same audio better. We have the situation that there could be more than one language spoken." — Cheng Z., G2
Pricing
Universal Streaming starts at $0.15/hr pay-as-you-go. Universal-3 Pro Streaming (highest accuracy) runs $0.45/hr. Whisper Streaming at 99+ languages is $0.30/hr. Enterprise pricing is custom.
Bottom Line
AssemblyAI makes sense if you're running phone-based voice agents where accuracy on messy audio matters, particularly in healthcare or finance, where terminology precision and compliance carry real weight.
Teams that need TTS or a full-stack pipeline will need to bring in a separate provider.
6. Vapi: Best for Flexible Multi-Provider Orchestration
What it does: Voice agent platform covering orchestration, telephony, and call monitoring in one API, letting teams swap STT, LLM, and TTS providers as needed.
Best for: Developers and engineering teams that need full control over every component of their voice stack, from model choice to telephony provider and latency tuning.
Vapi has processed over 1 billion calls, with 2.5M+ agents built on the platform and 99.9% uptime for enterprise clients. It targets sub-500ms average latency and prices its hosting cost ($0.05/min) separately from provider costs.
Teams that bring their own API keys for STT, LLM, and TTS pay at cost with no markup.
Key Features
- Bring Your Own Keys (BYOK): Bring your own OpenAI, Deepgram, ElevenLabs, or any supported provider key. Vapi passes those costs through at cost.
- AI Guardrails: Built-in conversation guardrails are designed to reduce off-script responses and maintain data integrity across calls.
- Call Logs and Analytics: Track performance across each call, surface failure points, and iterate on your setup without redeploying infrastructure.
Pros and Cons
Pros:
✅ Over 1 billion calls processed, validated at enterprise scale in contact centers and sales
✅ Sub-500ms average latency, published on the official product page
✅ SMS/Chat at $0.005/msg, with multi-channel support beyond voice in the same platform
Cons:
❌ HIPAA is a $2,000/mo add-on, and SOC 2, PCI, SSO, and RBAC all require a Scale contract.
❌ Call history retention is limited to 14 days on the Build plan. Teams that need longer audit trails will have to upgrade to Scale.
❌ 10 concurrent lines included on Build, with additional lines at $10/line/mo. Higher volume requires a scale contract.
What Users Say
"After evaluating multiple Voice API platforms, we found that Vapi best met our requirements for building a multi-agent voice system on top of a Voice API layer." — Rahul Ajit, Product Hunt
"Voice AI isn't 100%." — Chris Daigle, Product Hunt
Pricing
The Build plan runs $0.05/min for Vapi hosting, with provider costs passed through at cost. Scale is an annual contract with volume pricing, custom concurrency, and SOC 2, HIPAA, and SSO included.
Bottom Line
Vapi is the right call for engineering teams with existing LLM or STT contracts they want to keep. The orchestration layer handles routing, monitoring, and telephony while every model decision stays in the team's hands.
7. Retell AI: Best for No-Code Voice Agent Setup
What it does: Voice AI platform for deploying phone agents through drag-and-drop workflows and real-time function calling, with pay-as-you-go pricing.
Best for: Teams that need to go from signup to live phone agent fast, with full platform access on every plan and no contract required.
Retell AI positions itself as a 3rd Gen Voice AI, an LLM-based platform designed for natural phone conversations. It delivers ~600ms latency through its own orchestration and turn-taking model.
Medical Data Systems put that to work, deploying Retell to handle 100% of inbound calls with a 30% transfer rate and collecting around $280,000 per month.
Key Features
- Agentic Framework: Design conversational call flows with built-in guardrails and full control over agent behavior. Minimal engineering required for basic deployments.
- Real-time function calling with preset functions: Book appointments, process payments, and transfer calls directly from within call flows.
- Knowledge Base with Streaming RAG: Knowledge base stays in sync with your latest website content, so agents typically draw from current data.
Pros and Cons
Pros:
✅ Pay-as-you-go with no platform fees, and all plans include full platform access with no feature gating
✅ 20 concurrent calls included for free, with additional capacity at $8/concurrent call/month, removable anytime
✅ HIPAA, SOC 2 Type II, and GDPR compliant, with full compliance coverage available on self-serve plans
Cons:
❌ The pay-as-you-go plan runs on shared infrastructure, which may affect reliability at high concurrent volumes. A dedicated server is available only on Enterprise.
❌ SSO, custom MSA, custom DPA, and custom BAA require an Enterprise contract
❌ AI Quality Assurance is charged at $0.10/min after the first 100 free minutes, which can add a notable cost for teams that monitor each call
What Users Say
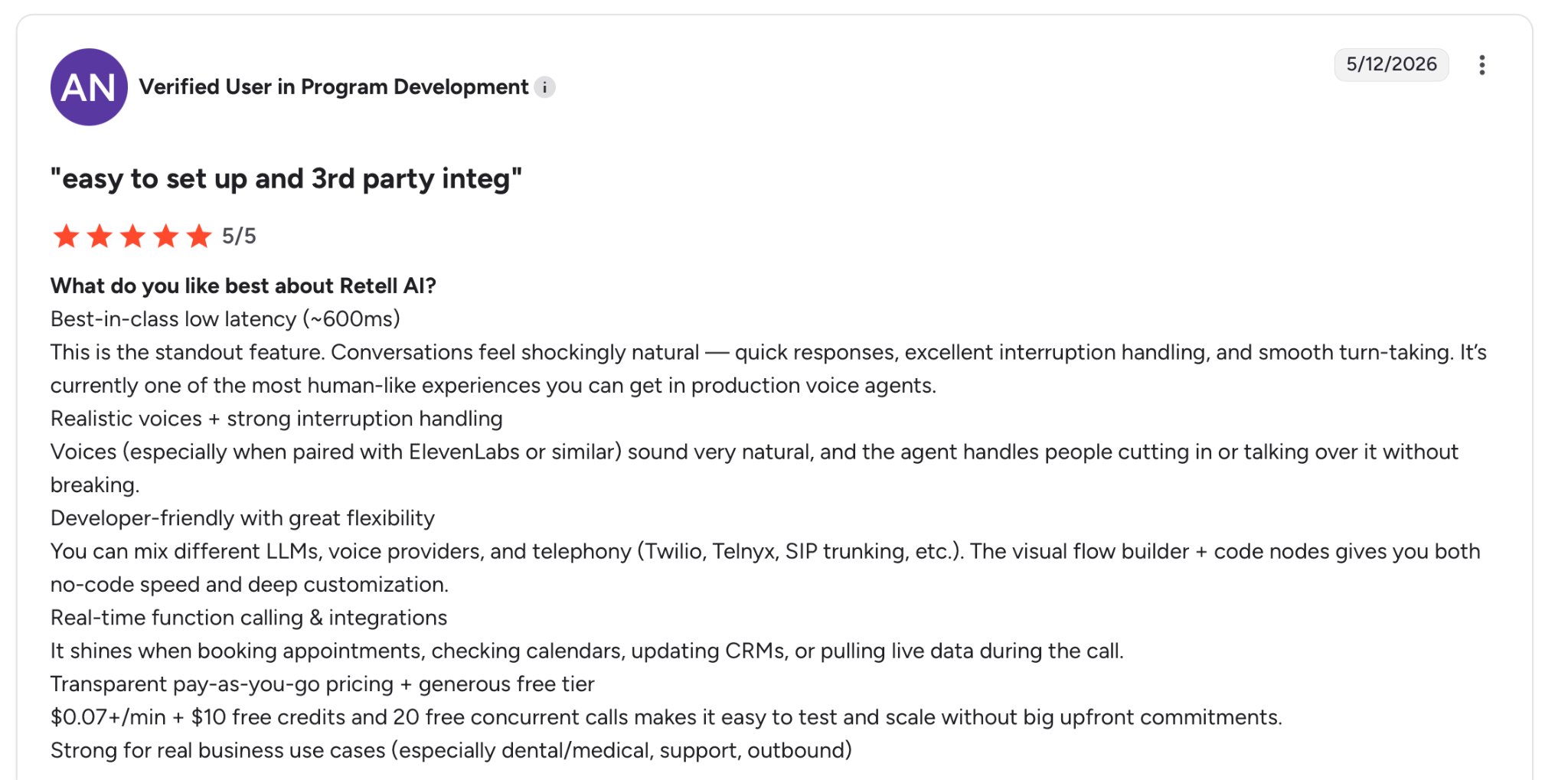
"Best-in-class low latency (~600ms). This is the standout feature. Conversations feel shockingly natural." — Verified User, G2
"The pricing model can become expensive when scaled to a very high call volume, especially when compared to 'in-house' implementations of open-source models." — Mili Pérez, G2
Pricing
Voice Infra starts at $0.055/min, with LLM and telephony billed on top. All-in costs range from $0.07 to $0.31/min. Enterprise is custom with a dedicated server and a custom BAA/DPA/MSA.
Bottom Line
If you need a phone agent live today, Retell AI is where to start. The pay-as-you-go model and full platform access across all plans make it a practical entry point on this list.
Which Voice AI API Should You Choose?
The best voice AI API for real-time audio processing depends on where you're building in the stack, whether you're assembling raw pipeline components, using a full-stack API, or deploying a ready-made phone agent.
Choose OpenAI Realtime API if you:
- Already built on OpenAI models and need GPT-5-class reasoning natively in the audio stream
- Need MCP server support and SIP telephony with no additional middleware to configure
Choose Inworld Realtime API if you:
- Want a full STT, LLM, and TTS pipeline in one endpoint, managed by a single provider
- Already on the OpenAI Realtime event schema and want to migrate with little rework
Choose Deepgram if you:
- Need high-accuracy STT as a standalone layer in a custom pipeline
- Operate in regulated industries where HIPAA and PCI compliance are required from day one
Choose ElevenLabs Conversational AI if you:
- Work in healthcare intake, premium customer support, real estate, or any use case where voice quality directly affects trust or conversion
- Need the broadest voice library (10,000+ voices, 70+ languages) in a single platform
Choose AssemblyAI if you:
- Need precise STT accuracy for phone-based agents handling domain-specific vocabulary in messy audio
- Run multilingual deployments across 99 languages as a standalone STT layer
Choose Vapi if you:
- Need granular control over every pipeline component
- Have existing provider contracts for STT, LLM, or TTS and want to pass costs through at zero markup
Choose Retell AI if you:
- Need a live phone agent running in hours, with full platform access on every plan, and billing to the nearest second
- Want pay-as-you-go pricing with no platform fees and no contract required
Skip this category entirely if:
- You need on-device, fully offline voice processing. All seven platforms require cloud connectivity. Edge and air-gapped deployments aren't supported by any of them.
- Your use case requires real-time voice translation across 50+ language pairs. Coverage gaps exist across all seven platforms.
Final Verdict
Choosing the best voice AI API for real-time audio processing comes down to where you're building in the stack.
OpenAI and Inworld lead on pipeline capability. Deepgram and AssemblyAI win on transcription precision. ElevenLabs leads on voice quality, and Retell AI is the fastest path to a working phone agent.
If I had to pick one for a team starting from scratch today, I'd go with Vapi for its component-level control and at-cost provider pricing. It'll let you swap components as better models emerge. ElevenLabs is also worth a serious look for teams where voice quality is the primary decision driver.
Are You Testing Your Voice AI API in Production?
The seven platforms above cover how you build and ship voice agents. Production failures in real-time audio processing tend to show up as confused callers and missed intents, and most only become visible at production call volumes.
That testing layer, covering both pre-production simulations and post-launch monitoring, sits on top of whatever platform you're using.
Cekura adds that testing and monitoring layer. That includes:
- Automated Simulations: Thousands of simulated calls run before go-live, catching the edge cases that emerge when real people push your agent off-script.
- Security Testing and Red Teaming: Stress-test your agent against adversarial inputs and off-script caller behavior before any of it reaches a real customer.
- Latency tracking: Cekura pinpoints where slowdowns originate in the pipeline so you know exactly what to fix after each provider swap or prompt update.
- CI/CD integration: Every time you update a prompt or swap a provider, Cekura runs your full test suite before anything goes live.
- Custom Metrics: Score each call on accuracy and missed intents using predefined metrics or your own criteria.
Native integrations are available for Retell, VAPI, ElevenLabs, LiveKit, Pipecat, Bland, and more.
The layer drops in on top of your existing stack.
Cekura's also SOC 2-, HIPAA-, and GDPR-compliant, with transcript redaction, role-based access, and audit trails included.
Most issues surface only in live calls. See how Cekura fits into your stack.
Frequently Asked Questions
What Is the Best Voice AI API for Real-Time Audio Processing?
The best voice AI API for real-time audio processing depends on where you're building in the stack. OpenAI and Inworld lead on full-stack pipelines. Deepgram and AssemblyAI lead on transcription accuracy. ElevenLabs leads on voice quality. Vapi and Retell AI cover orchestration and deployment.
What Latency Is Acceptable for Real-Time Voice AI?
A well-optimized real-time voice AI pipeline typically runs 500 to 800ms end-to-end. Time to first audio is a key metric to benchmark. Customer support agents can tolerate slightly longer. Companion or tutoring apps tend to benefit from staying closer to 500ms.
What Is the Difference Between an STT+LLM+TTS Pipeline and a Real-Time S2S API?
The main difference between an STT+LLM+TTS pipeline and a real-time S2S API is architecture. A chained pipeline runs three sequential steps, with latency accumulating at each stage.
A speech-to-speech API overlaps those stages in one endpoint, so the user hears audio while the model's still generating, which tends to produce a faster perceived response.
Can I Mix and Match STT, LLM, and TTS Providers in a Voice AI API?
Yes, but it depends on the platform. Vapi and Deepgram's Voice Agent API are built for this, letting you swap each component independently. Full-stack APIs like OpenAI Realtime and Inworld manage the entire pipeline internally, so component-level swapping isn't available on those.
Which Voice AI API Is Best for Healthcare Deployments?
The best voice AI APIs for healthcare deployments are AssemblyAI and ElevenLabs. AssemblyAI offers a Medical Mode add-on with HIPAA BAA on request. ElevenLabs provides HIPAA compliance via BAA on Enterprise. Deepgram, Vapi, and Retell AI also cover HIPAA, though some charge it as a paid add-on.