
What is the best AI voice API for developers? I've tested these across multiple production projects, including appointment booking bots and outbound sales agents. This guide ranks seven options, from full-stack orchestration to STT and TTS, so you can pick the right one for your stack.
7 Best AI Voice APIs for Developers: Quick Comparison
One thing stands out after testing these in real deployments. The price you see on the homepage is rarely the price you pay in production. A live agent with an LLM and a telephony layer running underneath will cost more once you're at volume.
| 💻 Tool | ⚡ Strengths | 🎯 Best For | 💰 Starting Price |
|---|---|---|---|
| VAPI | Full-stack orchestration, modular STT/LLM/TTS, sub-500ms latency | Developers building managed voice agents with full provider flexibility | $0.05/min (VAPI hosting fee) + provider costs |
| Deepgram | Nova-3 accuracy, Flux for real-time agents, under 300ms STT latency streaming | STT layer for production voice agents at scale | $0.0048/min (Nova-3 STT, Pay As You Go streaming) |
| OpenAI Realtime API | Native speech-to-speech, single-model voice loop, no STT/TTS split | Developers who want a unified audio in/out model | $32.00/1M audio model input tokens (GPT-Realtime-2) |
| AssemblyAI | Universal-3 Pro accuracy, audio intelligence beyond plain transcription (sentiment, PII, topics) | STT + post-call analysis beyond plain transcription | $0.21/hr (Universal-3 Pro, pay-as-you-go) |
| Retell AI | Managed platform, built-in telephony, full-stack deployment | Teams shipping phone agents to production fast | $0.07/min (AI Voice Agents, pay-as-you-go) |
| ElevenLabs | Voice realism, voice cloning, multilingual, streaming TTS | Agents where voice quality drives user trust | $6/month (Starter, billed monthly) |
| Cartesia | Sub-100ms TTFB, Sonic streaming-first, voice cloning, telephony | Real-time agents where latency is the top constraint | $4/month (Pro) |
How I Researched and Tested These AI Voice APIs
To build this list, I spent time with each API signing up for free tiers, running test calls, and reading official documentation. I also reviewed developer discussions on Reddit and GitHub to cross-check real-world experience against what vendors publish. Here's what I evaluated:
- Features: How well each API handles its core function. Transcription accuracy under noise, voice naturalness at streaming speed, or end-to-end conversation flow management.
- Latency: TTFB for TTS, real-time factor for STT, and full round-trip response time for orchestration platforms. Measured under realistic agent conditions, not synthetic benchmarks.
- SDK and DX: Documentation quality, SDK completeness across Python and Node.js, and how much setup is needed to get a working agent off the ground.
- Ecosystem fit: How cleanly each API connects with the rest of a standard voice stack, including LLMs, telephony providers, orchestration layers, and monitoring tools.
- Pricing transparency: What the real cost looks like at production volume, beyond the headline free tier.
What is the best AI voice API for developers? Running through all of that helped clarify the answer at each layer of the stack, and which ones look better on paper than they perform in practice.
7 Best AI Voice APIs for Developers
1. VAPI: Best for Full-Stack Voice Agent Orchestration
What it does: VAPI is an orchestration layer that connects your STT, LLM, and TTS providers into a single real-time voice pipeline, managing latency optimization, streaming, scaling, and conversation flow.
Best for: Developers who need full provider flexibility and want to go from prompt to production-ready voice agent fast, without building the infrastructure layer themselves.
VAPI lets you swap any provider (Deepgram, ElevenLabs, Cartesia, OpenAI, Claude, Gemini) without rebuilding the pipeline. Running it on an appointment booking agent and changed transcription providers mid-project in under five minutes with no latency regression. Where it gets messy is the billing. You're tracking charges across platform, transcription, language model, voice synthesis, and telephony simultaneously, and HIPAA compliance adds $2,000/month on top of all that.
Key Features
- Modular STT/LLM/TTS stack: Swap any provider independently, or bring your own API keys and pay model costs at cost with $0 VAPI markup.
- Sub-500ms average latency: Streaming pipeline tuned for real-time conversation quality at scale.
- VAPI Workflows: Visual and code-based orchestration for multi-step conversation flows.
- VAPI Monitoring: Production call monitoring with real-time observability across all active agents.
- Enterprise compliance: SOC 2, HIPAA, and PCI compliant, with SSO and RBAC available on the Scale plan.
Pros
✅ True provider modularity with no lock-in on any layer of the stack
✅ 1M+ developer community with extensive documentation and pre-built patterns
✅ Enterprise-grade uptime SLA on Scale plans
Cons
❌ Layered billing across platform, STT, LLM, TTS, and telephony makes cost forecasting harder at high call volume
❌ HIPAA compliance isn't included in base plans and requires a separate paid add-on
What Users Say
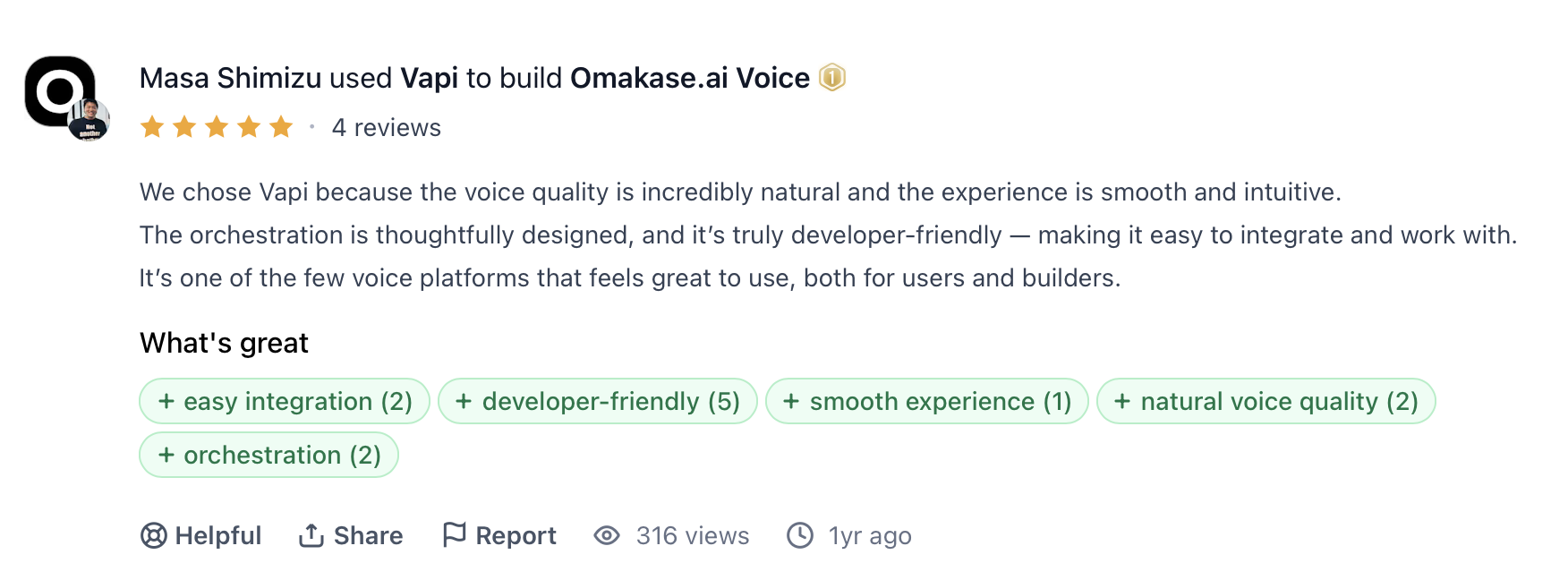
"We chose VAPI because the voice quality is incredibly natural and the experience is smooth and intuitive." — Masa Shimizu, Product Hunt
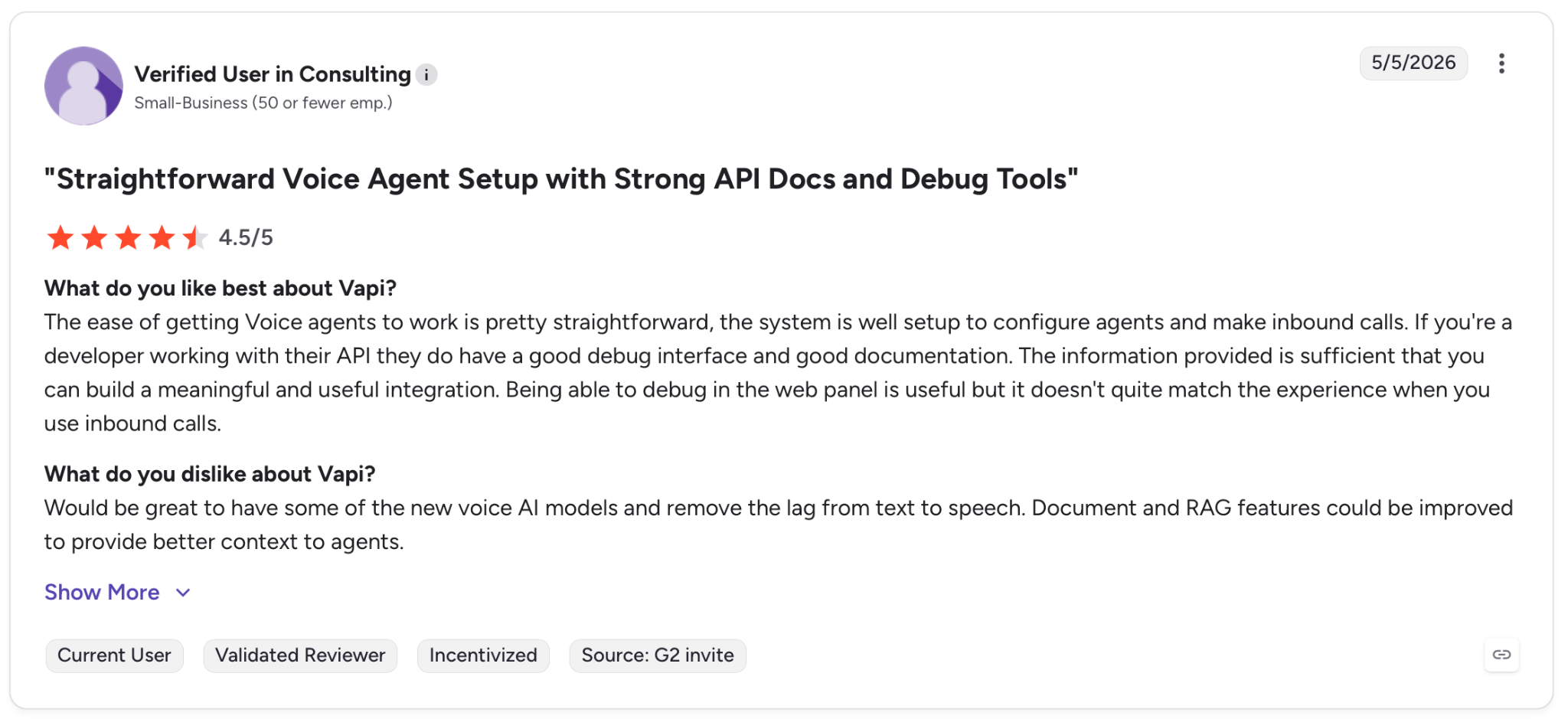
"It would be great to have some of the new voice AI models and remove the lag from text to speech." — Verified User, G2
Pricing
Build plan runs starting at $0.05/min as a VAPI hosting fee, with provider costs billed at cost on top. Bring your own API keys and the VAPI markup drops to $0. For Scale and Enterprise, contact sales.
Bottom Line
VAPI makes sense when provider flexibility and orchestration depth matter more than simplicity. If you need HIPAA compliance, factor the $2,000/mo add-on into your evaluation from day one.
2. Deepgram: Best for Low-Latency STT in Production Voice Agents
What it does: Deepgram provides speech-to-text APIs built specifically for real-time voice agents, with two distinct models: Flux for conversational agents and Nova-3 for high-accuracy transcription at scale.
Best for: Developers who need a dedicated, production-grade STT layer with sub-300ms latency and enterprise reliability across 50+ languages.
Deepgram gives you two models under one API that solve different problems. Flux handles live conversation with turn detection, end-of-thought signals, and interruption handling. Nova-3 targets accuracy across noisy, multilingual audio. You switch between them without changing your integration. I tested Flux on an outbound sales agent with frequent cross-talk and it handled the overlapping speech cleanly. The end-of-thought detection cuts dead air, though the 10-language ceiling on Flux is a real constraint if your deployment goes multilingual.
Key Features
- Flux: Conversational STT with built-in turn detection, end-of-thought detection, and native interruption handling, built for voice agents in 10 languages.
- Nova-3: High-performance STT for production transcription with strong noise handling and multilingual support across 50+ languages.
- Keyterm Prompting: Up to 90% higher keyword recall rate for domain-specific vocabulary, important for healthcare, legal, and finance use cases.
- Speaker Diarization + PII Redaction: Multi-speaker detection and automatic sensitive data removal, available as add-ons.
- Voice Agent API: Full end-to-end conversational agent API with STT, LLM, and TTS in a single pipeline, with BYO LLM and BYO TTS options.
Pros
✅ Two purpose-built models (Flux for real-time agents, Nova-3 for accuracy-first transcription) under a single API
✅ Transcripts in under 300ms, built for real-time conversational AI
✅ $200 free credit with no credit card required to start
Cons
❌ Flux supports only 10 languages. Nova-3 covers 50+ but is not built for real-time agent use
❌ Audio Intelligence features (sentiment, topics, intent) are priced separately and compound cost at analytics-heavy workloads
What Users Say
"I appreciate how fast Deepgram is when using it for real-time production applications, as even small delays can make a big difference." — Neha S., G2
"While Deepgram performs very well overall, the pricing can become expensive when processing large volumes of audio." — Bhanu Prakash V., G2
Pricing
Nova-3 Monolingual starts at $0.0048/min on pay-as-you-go (limited-time promotional rate). Flux English runs $0.0065/min. The Growth plan ($4K+/year) brings both down by up to 20%.
Bottom Line
If STT latency is your primary bottleneck, Deepgram's Flux model addresses it more directly than the other options here. Teams building multilingual agents will want Nova-3, and can layer the Voice Agent API on top when ready to consolidate the full pipeline.
3. OpenAI Realtime API: Best for Native Speech-to-Speech Agents
What it does: The OpenAI Realtime API enables low-latency, native speech-to-speech interactions, audio in and audio out, without splitting the pipeline into separate STT and TTS components.
Best for: Developers who want a single-model voice loop with multimodal input support (audio, text, images) and don't want to manage a layered STT/LLM/TTS stack.
The OpenAI Realtime API processes audio in and audio out in a single model pass, skipping the transcribe-then-synthesize chain. That removes compounding latency and, according to OpenAI, preserves prosody and tone that get lost when audio passes through a transcription step. On a support agent already running on GPT-5.5, it was live in under five minutes. The tradeoff is in the bill. At $32/1M audio input tokens, the cost scales fast under real call volume. A layered stack with a dedicated transcription provider and a cheaper language model will come in cheaper.
Key Features
- Native speech-to-speech: Audio in, audio out in a single model pass with no separate STT or TTS layer needed.
- Multimodal inputs: Accepts audio, text, and image inputs simultaneously in the same session.
- Three connection methods: WebRTC for browser and client, WebSocket for server-side, SIP for VoIP telephony, same model across all transports.
- Function calling + MCP: Give the real-time model access to custom code and external data via tool calls and Model Context Protocol servers.
- GPT-Realtime-Whisper: Dedicated streaming STT model for real-time transcription at $0.017/min, usable independently from the full S2S model.
Pros
✅ Single model pass removes the latency of separate STT, LLM, and TTS calls
✅ Preserves natural prosody and tone that transcription-based pipelines lose
✅ WebRTC, WebSocket, or SIP from the same API with no integration changes
Cons
❌ No provider choice. The full voice pipeline runs on OpenAI's model only
❌ Voice cloning is not currently supported
What Users Say

"I like ChatGPT's real-time API, which is perfect for real-time speech to speech functionality with very little latency." — Rehman T., G2
"Realtime-2 with a 200ms response is incredible until you put a RAG layer in front, and it becomes 800ms because the embedding lookup + rerank + filter chain is the slow path." — Verified User, Reddit
Pricing
GPT-Realtime-2 bills on audio tokens starting at $32.00/1M input and $64.00/1M output. New accounts receive API credits to start; there's no free plan beyond that.
Bottom Line
The OpenAI Realtime API fits best when conversation naturalness is the top priority and cost-per-minute is secondary. If you're running high call volume and need to cut spend, a layered stack with Deepgram and a cheaper LLM will cost less at scale.
4. AssemblyAI: Best for STT with Built-In Audio Intelligence
What it does: AssemblyAI provides speech-to-text APIs with a modular intelligence layer on top, covering sentiment analysis, entity detection, topic classification, PII redaction, and speaker diarization all from the same API.
Best for: Developers building voice agents that need more than raw transcription, including post-call analysis, compliance monitoring, clinical documentation, or conversation intelligence at high volume.
AssemblyAI separates into two layers, the transcription model and the Speech Understanding API on top. You run just transcription, or add sentiment, entities, topics, and PII redaction modularly without changing your core integration. I tested it on a healthcare scheduling scenario with drug names and overlapping speakers. Medical Mode reduced missed entities and PII redaction worked out of the box. Teams that only need transcription will find the all-in Voice Agent API at $4.50/hr compounds fast.
Key Features
- Universal-3 Pro: Highest accuracy STT for noisy, messy audio, tuned for entities, rare words, alphanumerics, and overlapping speech with sub-300ms streaming transcripts.
- Speech Understanding API: Modular intelligence layer covering sentiment analysis, entity detection, topic classification, speaker diarization, and translation, all from a single API call.
- LLM Gateway: Send transcripts directly to GPT, Claude, Gemini, or 25+ open-source models with 0% markup and automatic fallbacks.
- Medical Mode: Approximately 20% reduction in missed entities on drug names, conditions, and procedures. HIPAA BAA available.
- Self-Hosted deployment: Run AssemblyAI models on your own infrastructure for data sovereignty, reduced network latency, and full stack control.
Pros
✅ Modular intelligence stack lets you add sentiment, PII, entities, or topics without changing core STT integration
✅ Self-hosted option available with the same models and same API on your own infrastructure
✅ LLM Gateway with 0% markup and automatic fallbacks removes a layer of integration work
Cons
❌ Not purpose-built for sub-200ms real-time agent latency the way Deepgram Flux is
❌ Universal-3 Pro Streaming is available in 6 languages at launch. Broader language support requires the async model
What Users Say
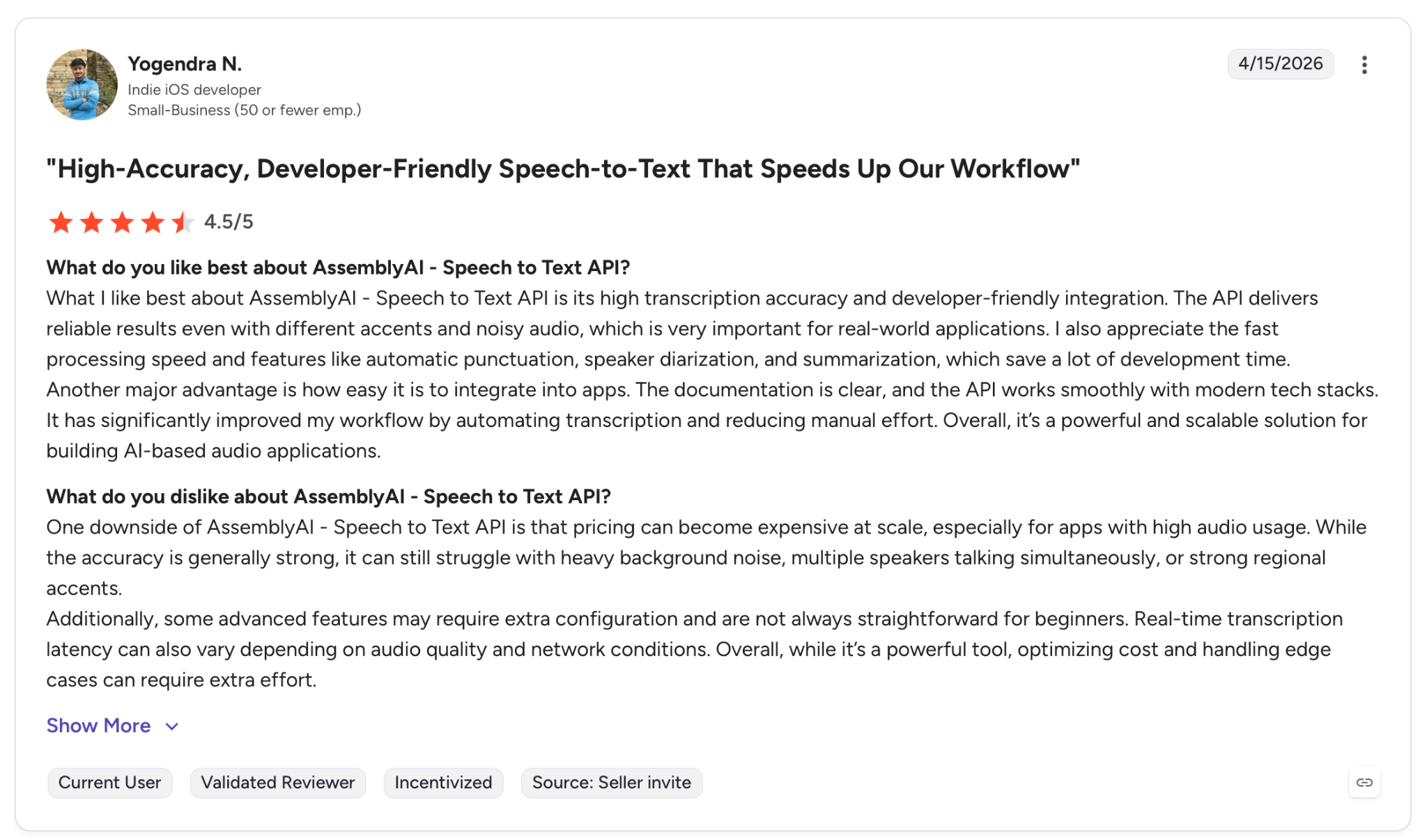
"What I like best about AssemblyAI's speech-to-text API is its high transcription accuracy and developer-friendly integration." — Yogendra N., G2
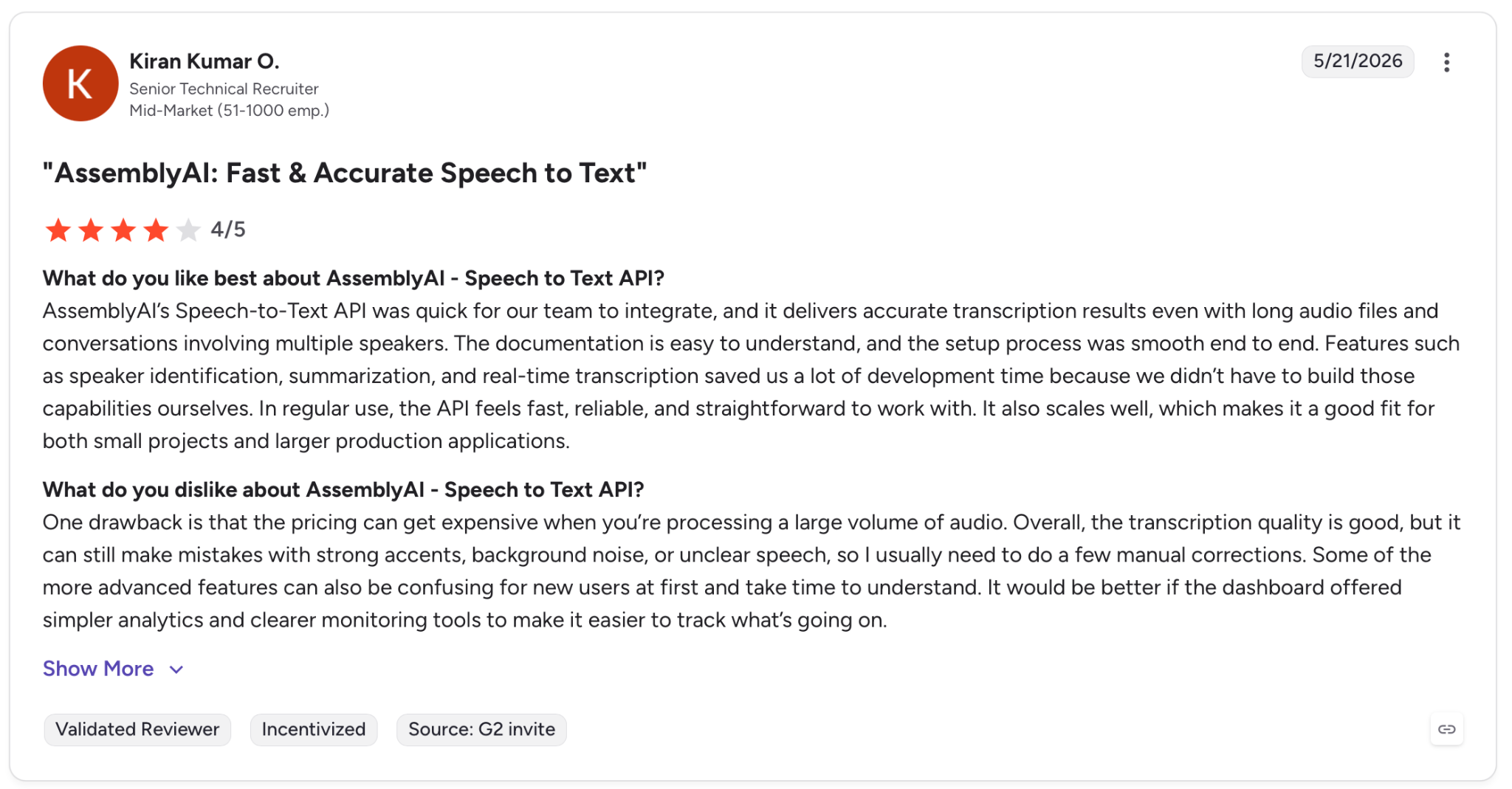
"One drawback is that the pricing can get expensive when you're processing a large volume of audio." — Kiran Kumar O., G2
Pricing
Universal-3 Pro runs starting at $0.21/hr for both async and streaming, with unlimited concurrent streams. The all-in Voice Agent API (speech, LLM, and TTS bundled) is $4.50/hr. Free tier available with no credit card required.
Bottom Line
AssemblyAI works best when transcription accuracy and post-call intelligence matter as much as the conversation itself, particularly in healthcare and compliance-heavy industries. If raw transcription latency for real-time agents is the primary constraint, Deepgram Flux will serve you better.
5. Retell AI: Best for Managed Full-Stack Phone Agent Deployment
What it does: Retell AI is a full-stack, managed voice agent platform that handles the entire call pipeline, including STT, LLM, TTS, telephony, and orchestration, so you can go from signup to a live phone agent in minutes.
Best for: Engineering teams that need to ship production-ready phone agents fast, with built-in telephony, omnichannel support, and enterprise compliance out of the box.
Retell runs transcription, language model, voice synthesis, and telephony as a single managed pipeline with HIPAA, SOC 2, and GDPR compliance included at no extra cost. Starting from a cold account and had a live inbound agent taking calls in under 15 minutes using the drag-and-drop flow builder with no code written. That speed comes with a constraint though. Retell locks you into its supported LLM and TTS options, so teams that need a specific model combination outside that list will need VAPI instead.
Key Features
- Native Voice AI Orchestration: Built-in turn-taking model, interruption handling, and ultra-realistic voices trained on real performance data.
- Agentic Framework: Drag-and-drop call flow builder with built-in guardrails, real-time function calling, and preset functions for appointment booking, payments, and CRM updates.
- Streaming RAG: Knowledge base that auto-syncs with your latest website content for accurate, real-time answers in every call.
- Omnichannel: Voice, chat, and SMS on the same agent framework with no separate integrations needed.
- Enterprise compliance: HIPAA, SOC 2 Type I and II, GDPR, with BAA available at no additional cost.
Pros
✅ Full platform access on every plan with no feature gating and no platform fees
✅ HIPAA, SOC 2 Type II, and GDPR compliance with BAA at no additional cost
Cons
❌ Less provider flexibility than VAPI, as the platform is locked into Retell's supported LLM and TTS options
❌ Conversation endpointing runs at approximately 600ms by default, which can feel slow in latency-sensitive deployments
What Users Say
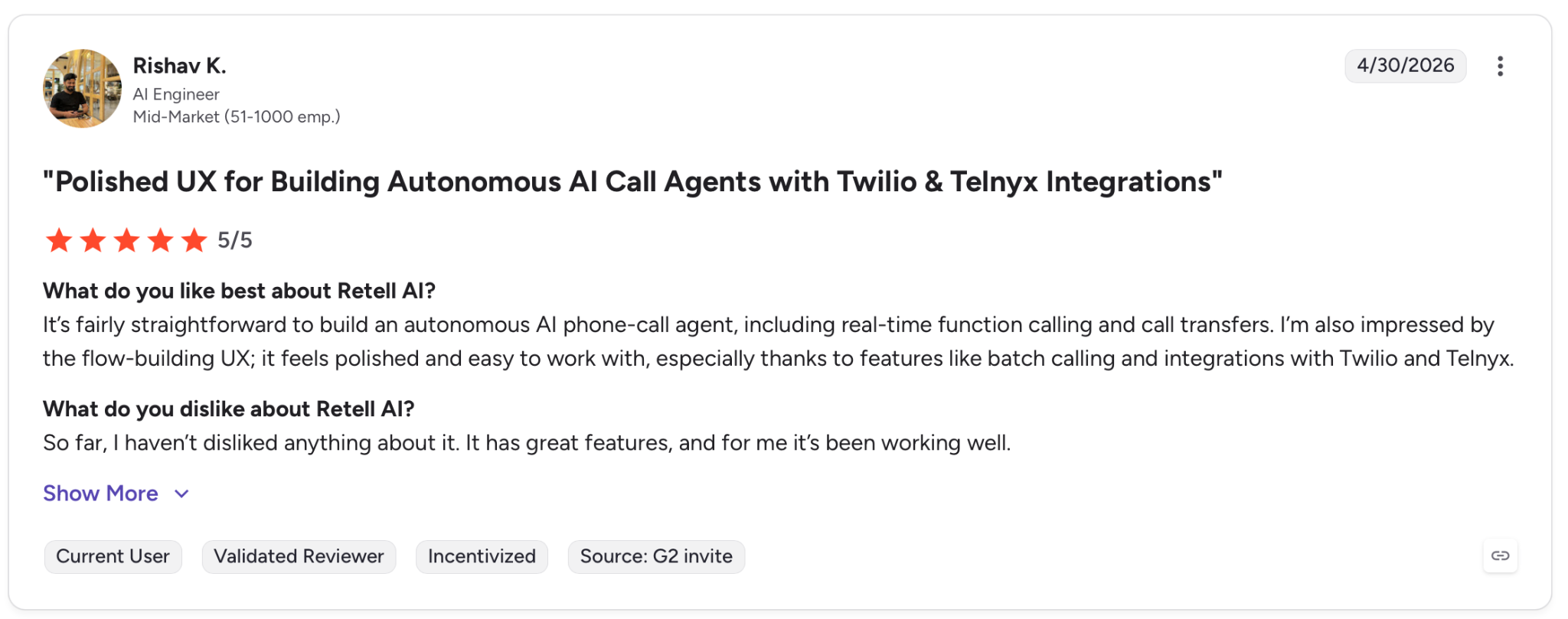
"It's fairly straightforward to build an autonomous AI phone-call agent, including real-time function calling and call transfers." — Rishav K., G2
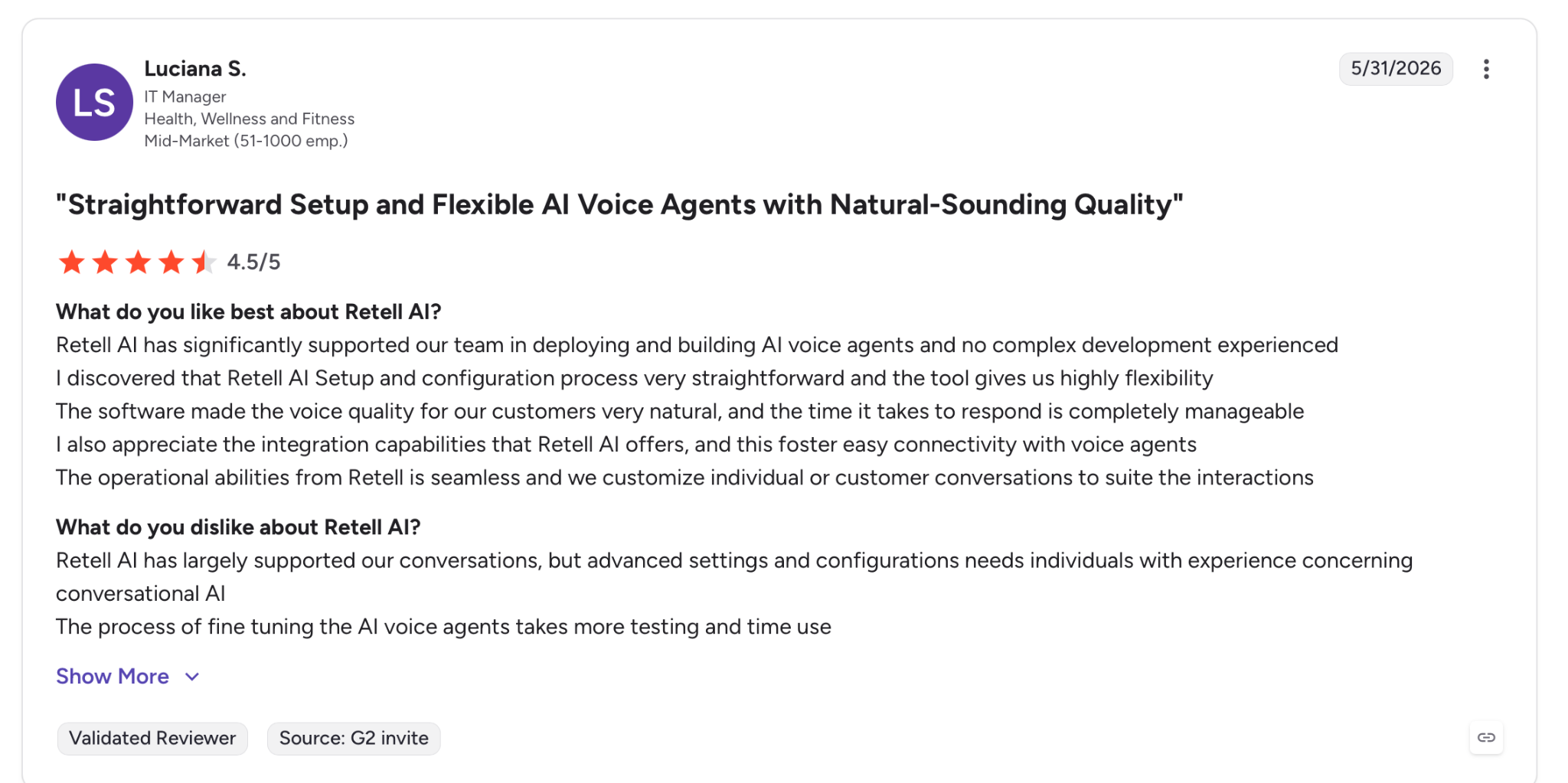
"Retell AI has largely supported our conversations, but advanced settings and configurations need individuals with experience concerning conversational AI." — Luciana S., G2
Pricing
Pay-as-you-go starts at $0.07/min for AI Voice Agents, with $10 in free credits on signup. Enterprise pricing on request.
Bottom Line
Retell's the shortest path from zero to a live phone agent on this list. HIPAA and SOC 2 compliance with no add-on fees makes it a strong option for healthcare and regulated industries.
6. ElevenLabs: Best for Voice Quality and Multilingual Agents
What it does: ElevenLabs provides TTS, STT, voice cloning, and a fully managed voice agents platform, all accessible through a single API with official SDKs for Python and TypeScript.
Best for: Developers building agents where voice realism, emotional expressiveness, and multilingual support are non-negotiable, and teams that want a single API for TTS, STT, and full agent orchestration.
ElevenLabs covers the full voice stack in one API. Voice synthesis runs via Eleven Flash v2.5 at approximately 75ms, speech recognition via Scribe v2 across 90+ languages, and full agent orchestration through ElevenAgents with built-in turn-taking and phone integration. I tested it on an inbound support agent and the pacing held up better than the other tools I tested. The turn-taking model stopped the agent from cutting in mid-sentence, which is harder to get right than it sounds. HIPAA BAA is locked to Enterprise. That rules out ElevenLabs for healthcare teams on a self-serve plan.
Key Features
- Eleven v3 (TTS): Most expressive TTS model with nuanced intonation, pacing, and emotional awareness across 10,000+ voices in 70+ languages.
- Eleven Flash v2.5: Ultra-low latency TTS at approximately 75ms, designed for real-time streaming in voice agents.
- Scribe v2 (STT): Streaming and batch STT across 90+ languages with approximately 150ms realtime latency.
- Voice Cloning: Instant voice cloning from Starter plan. Professional Voice Cloning from Creator plan.
- ElevenAgents: Fully managed voice agent platform covering STT, LLM, TTS, and turn-taking model, with knowledge bases, phone integration, and multi-turn conversation management.
Pros
✅ Single API for TTS, STT, voice cloning, and full agent orchestration with no separate providers needed
✅ Eleven Flash v2.5 at approximately 75ms is competitive with Cartesia on latency, with higher voice quality to show for it
✅ 10,000+ voices across 70+ languages with professional cloning available from $22/mo (first month $11)
Cons
❌ HIPAA BAA only available on Enterprise plan, not accessible on any self-serve tier
❌ API usage and subscription credits appear to bill separately, which can make it harder to track total spend in one place
What Users Say
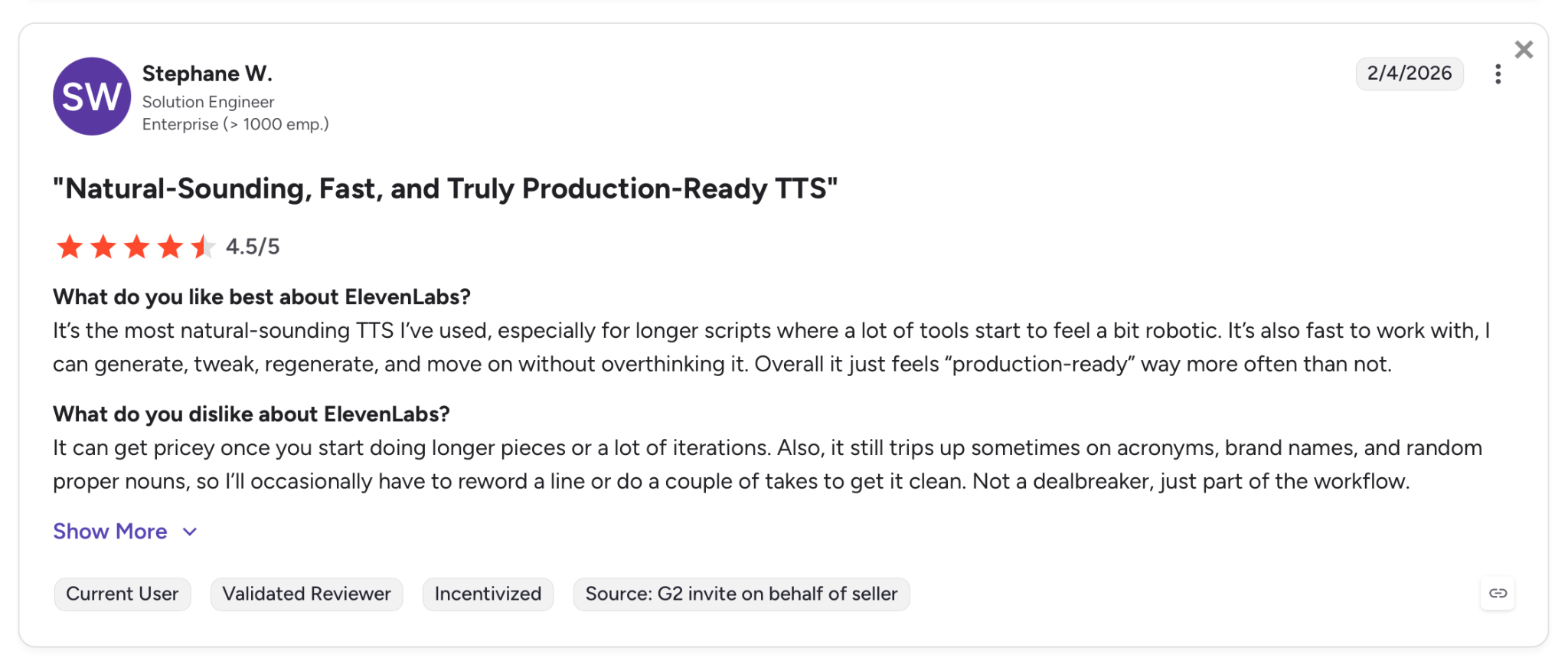
"It's the most natural-sounding TTS I've used, especially for longer scripts where a lot of tools start to feel a bit robotic." — Stephane W., G2
"Been using the Elevenlabs v3 for a bit, but sometimes it provides an artifact at either the starting or the end (random note) which basically causes an issue in my API's implementation, and when I use v2, the overall realism is not achieved as achieved by v3." — Kush A., G2
Pricing
The starter plan begins at $6/mo includes 30,000 credits, a commercial license, and instant voice cloning. Creator at $22/mo (first month $11) adds professional voice cloning and 121,000 credits. Enterprise pricing on request.
Bottom Line
ElevenLabs leads on voice quality and multilingual coverage. If you need HIPAA compliance without an enterprise contract, Retell AI covers that gap.
7. Cartesia: Best for Ultra-Low Latency Real-Time Voice Agents
What it does: Cartesia provides TTS (Sonic), STT (Ink-2), and a full voice agents platform (Line), all built on State Space Models (SSMs) designed for live, synchronous interactions with sub-90ms latency.
Best for: Developers where latency is the hard constraint, including real-time agents, live customer service, and any use case where response delay directly impacts user experience.
Cartesia's stack runs on State Space Models instead of transformers, which is what keeps Sonic's published TTFA at sub-90ms. Ink-2 handles streaming transcription at high concurrency, and both run across cloud, on-premise, VPC, and on-device from the same API. I tested Sonic on interruption-heavy calls, and the agent responded before the caller registered a pause. For regulated or non-English deployments, check the 40+ language library and Enterprise-only compliance before committing.
Key Features
- Sonic-3.5 (TTS): Ranked #1 for naturalness with sub-90ms latency, 40+ languages, instant and professional voice cloning, voice changer, and voice localization.
- Ink-2 (STT): Lowest-cost streaming transcription model in Cartesia's stack, built for real-time agents with high concurrency.
- Line (Voice Agents): Full voice agent platform at $0.06/min call duration + $0.014/min telephony, with free LLM usage for UI-created agents (limited time).
- Deployment options: Cloud regional endpoints, VPC, on-premise, and on-device with the same models across all deployment modes.
- Enterprise compliance: SOC 2 Type II, GDPR, PCI. DPAs and BAAs for HIPAA available on Enterprise plan.
Pros
✅ Sub-90ms TTS latency ranked #1 for naturalness, the fastest on this list for real-time agents
✅ Identical models across cloud, VPC, on-premise, and on-device with no re-integration needed
Cons
❌ DPAs and BAAs for compliance are only available on Enterprise, not on any self-serve plan
❌ Narrower ecosystem and community compared to ElevenLabs and VAPI
What Users Say

"Looks like it supports realtime streaming, which would be a great improvement over Whisper." — Verified User, Reddit
"The cloning is very good, as well as the localization. I don't think they're quite there for the quality of the TTS for languages other than English, but I'd say they're one of the best contenders to compete with 11labs." — Verified User, Reddit
Pricing
Pro plan starting at $4/mo includes 100,000 credits, approximately 133 min of TTS and 9h 16m of STT, with instant voice cloning included. Enterprise pricing on request.
Bottom Line
Pick Cartesia when latency is the primary engineering constraint and deployment flexibility across cloud, VPC, and on-device matters as much as model quality. If you need HIPAA compliance on a self-serve plan, Retell AI is the more accessible option.
Which AI Voice API Should You Choose?
What is the best AI voice API for developers? The right answer depends entirely on where you sit in the stack and what constraint you're optimizing for.
Choose VAPI if you:
- Need full provider flexibility across STT, LLM, and TTS without vendor lock-in
- Want a production-grade orchestration layer without building the infrastructure yourself
- Are running a modular stack and want to swap providers independently as the market evolves
Choose Deepgram if you:
- Need the lowest-latency STT layer for a real-time voice agent. Flux delivers under 300ms
- Are building a multilingual transcription pipeline at scale. Nova-3 covers 50+ languages
- Want STT plus audio intelligence (sentiment, entities, PII) from a single provider
Choose OpenAI Realtime API if you:
- Want a single-model speech-to-speech loop without managing a layered STT/LLM/TTS pipeline
- Are building agents where natural prosody and tone matter more than per-minute cost
- Already run on OpenAI's ecosystem and want to minimize provider surface area
Choose AssemblyAI if you:
- Need post-call intelligence (sentiment, entities, topic classification, compliance monitoring) on top of transcription
- Are in healthcare or a compliance-heavy vertical and need Medical Mode with HIPAA BAA
- Want self-hosted STT on your own infrastructure with the same API
Choose Retell AI if you:
- Need a fully managed phone agent platform with built-in telephony, fast deployment, and no feature gating
- Require HIPAA and SOC 2 compliance without enterprise-level add-on costs
- Are shipping omnichannel agents across voice, chat, and SMS on a single framework
Choose ElevenLabs if you:
- Need strong voice quality and multilingual coverage. 10,000+ voices across 70+ languages
- Want TTS, STT, voice cloning, and agent orchestration from a single API
- Are building consumer-facing agents where voice realism directly impacts engagement
Choose Cartesia if you:
- Have latency as your primary hard constraint. Sub-90ms TTS is the fastest on this list
- Need deployment across cloud, VPC, on-premise, and on-device from the same API
- Are building synchronous real-time voice interactions where response delay directly affects user experience
Skip this category entirely if:
- Your use case is one-shot audio generation, not conversational agents. Simpler TTS-only tools will serve you better
- You haven't validated your agent's core conversational flow yet. Most of these APIs have free tiers worth starting with before committing to a paid stack
Final Verdict
If you need to ship fast with compliance included, Retell AI is the shortest path from signup to a live phone agent. If you need full control over every layer of the stack, VAPI is where developers with modular requirements tend to start.
For individual layers: Deepgram Flux on STT latency, AssemblyAI when you need intelligence on top of transcription, ElevenLabs on voice quality and multilingual breadth, Cartesia when response time is the hard constraint.
The OpenAI Realtime API fits when you want to skip the transcription step entirely. What is the best AI voice API for developers? If you're still working that out for your specific stack, the comparison table at the top maps each one to its primary use case.
How to Know Your Voice API Stack Holds Up Once It Goes Live
Every API on this list gives you a voice pipeline. None of them tells you whether your agent performs once a real caller is on the line. Teams usually find out something's wrong after the fact, when a caller drops, or a transcript comes back wrong.
Cekura runs on top of whichever provider you choose and closes that gap through:
Pre-production
- Automated simulations: Thousands of simulated calls run before go-live, catching the edge cases that only surface when real callers push your agent off-script.
- Regression testing: Every time you swap a TTS model, update a prompt, or change a voice provider, Cekura runs your full test suite before anything goes live.
- A/B testing: Compare multiple versions of your agent against the same call scenarios and review results in one place.
Infrastructure
- Interruption detection: When the agent talks over a caller or cuts off mid-sentence, Cekura flags those timing patterns in the test report.
- Latency tracking: Measures where slowdowns originate in the pipeline so you know exactly what to fix after each update.
Observability
- Production call QA: Monitors live calls for drop-off points, negative sentiment, and workflow adherence across volumes that manual review can't cover.
- Conversation replay: When something breaks in production, replay that exact exchange against your updated configuration to confirm the fix held.
- Custom evaluation: Score every call on accuracy, missed intents, and incorrect responses using your own criteria.
Native integrations work out of the box for Retell, VAPI, ElevenLabs, LiveKit, Pipecat, Bland, and more.
You don't rebuild anything. You add a testing and monitoring layer on top of what you already have.
It's SOC 2-, HIPAA-, and GDPR-compliant for transcript redaction, role-based access, and audit trails.
Building on one of these APIs and want to know if your agent holds up under real call volume? Schedule a demo with Cekura to see how it tests and monitors your stack in production.
Frequently Asked Questions
What Is an AI Voice API?
An AI voice API is a developer interface that converts text to speech (TTS), speech to text (STT), or handles both directions of a voice conversation in real time. Developers use them to add voice capabilities to products without building the underlying speech models themselves.
What Is the Difference Between STT and TTS APIs?
STT and TTS APIs handle opposite directions of voice. STT (speech-to-text) transcribes spoken audio into text. TTS (text-to-speech) converts text into spoken audio. Most production voice agents need both, and some providers like Deepgram and ElevenLabs offer both under a single API.
What Is the Best AI Voice API for Real-Time Agents?
For real-time agents, the best AI voice API depends on the layer. For full-stack orchestration, VAPI and Retell AI lead. For STT latency, Deepgram Flux delivers under 300ms. For TTS latency, Cartesia Sonic runs at sub-90ms. For teams that want a single-model speech-to-speech loop, the OpenAI Realtime API removes the STT and TTS split entirely.
Is VAPI Free?
No, VAPI does not have a free plan. New accounts receive $10 in credits to start. The Build plan charges $0.05/min as a platform fee, with provider costs billed on top. Bringing your own API keys removes the VAPI markup.
Does ElevenLabs Have a Free Plan?
Yes, ElevenLabs offers a free plan with 10,000 characters per month. The Starter plan at $6/mo increases that to 30,000 characters and adds a commercial license and instant voice cloning.