
The best Arize AI alternatives solve a problem that Arize wasn't designed for. The platform started as an ML monitoring tool, and it works, but teams building LLM agents in production keep hitting the same wall. Each tool here targets a different gap, with honest pricing and real cons included.
7 Best Arize AI Alternatives: At a Glance
Here's how they stack up before we get into the details.
| 🏆 Platform | 🎯 Best for | 💰 Price |
|---|---|---|
| Braintrust | CI/CD evaluation before release | $249/month |
| Langfuse | Self-hosted data control | $29/month |
| LangSmith | LangChain and LangGraph stacks | $39/seat/month |
| W&B Weave | W&B ecosystem teams | $60/month billed monthly |
| Fiddler AI | ML and LLM monitoring combined | $0.002/trace |
| Galileo | Eval-to-guardrail pipeline | $100/month billed annually |
| Opik by Comet | Automated code fixes from traces | $19/month |
*Pricing correct as of April 2026. Verify with the vendor.
Why Look for Arize AI Alternatives?
Arize has been in ML monitoring since 2020, raised $131M, and its open-source Phoenix framework has strong community adoption. For teams running traditional ML and LLMs together, it covers both. But teams shipping LLM agents hit specific walls like:
- The platform was built for ML monitoring first: LLM evaluation and agent tracing came later. Dataset management is separate from the tracing interface, so connecting evaluation results to specific production traces is a manual process.
- Enterprise pricing starts at $50,000 per year: Arize AX targets organizations with existing ML infrastructure. Teams that only need LLM observability end up paying for tooling they won't use.
- The interface is built for ML engineers: Product managers and domain experts who need to review outputs or annotate traces can't do it without engineering support, which adds friction to every quality iteration.
- No pre-production simulation: Arize focuses on what happens after deployment. Testing agent behavior across scenarios before launch means building your own tooling or scripting workarounds.
- CI/CD deployment blocking isn't native: Arize integrates with GitHub Actions but doesn't block deployments when evaluation scores drop. Catching regressions before users see them is a manual step, not an automated one.
Which Arize AI Alternative Should You Choose?
The right pick depends on where your stack breaks down today.
- Choose Braintrust if you want evaluation scores to block a release before it ships, not after a user reports it.
- Choose Langfuse if legal or compliance requirements prevent sending conversation data outside your own servers.
- Choose LangSmith if your entire stack runs on LangChain or LangGraph and you want traces captured with no extra setup.
- Choose W&B Weave if you already use Weights & Biases for model training and want LLM observability without adding a new vendor.
- Choose Fiddler AI if your team monitors both classical ML models and LLM agents and needs a single platform for both.
- Choose Galileo if you want the same quality checks running in development to become the guardrails enforcing standards in production.
- Choose Opik by Comet if you need full observability and evaluation with unlimited self-hosting and no feature restrictions.
- Stick with Arize if you run both traditional ML and LLM workloads, and the Phoenix open-source layer already covers what you need.
Add Cekura if you ship a voice or chat AI agent and need pre-production call simulation or live production monitoring. It runs on top of whichever observability tool you pick.
7 Best Arize AI Alternatives for LLM Teams in 2026
1. Braintrust
Braintrust is for teams that catch bad prompts before users do.
The platform covers tracing, offline experiments, output scoring, and dashboards for non-engineers. Companies like Notion and Zapier run it in production. The eval-first approach means quality checks happen before a prompt ships, not after a user complains.
"It's an all-in-one platform with evals tracking, observability, and playground tools for rapid experimentation." — Verified User, G2
Key Features
- Full tracing records every LLM call, agent span, and tool invocation across your stack with unlimited projects and datasets.
- Offline experiments run A/B comparisons between prompt and model versions, tracking regressions over time without usage caps.
- Loop Agent is a built-in agent that generates test cases, runs evaluations, and iterates on prompts without manual intervention.
- Environment tagging labels object versions as production, staging, or development so prompt pulls stay scoped to the right context.
- Public cost calculator covers two billing meters, processed data, and scored outputs, with an interactive estimator on the pricing page.
Pros
✅ Starter plan includes unlimited users, projects, datasets, and experiments at no cost, which is rare at this tier.
✅ SOC 2 Type II and multi-factor authentication ship on every plan, including free.
✅ The UI gives product managers direct access to annotation queues and dashboards without going through an engineer.
Cons
❌ Data retention caps at 30 days on Pro. Longer retention requires Enterprise. There's no middle option.
❌ Gemini grounding metadata gets dropped silently on streaming responses, so citation data never appears in traces.
❌ Perplexity and Mistral model requests are routed incorrectly through the proxy, so tracing for those providers is unreliable.
Best For
- Teams shipping LLM features that want evaluation built into the development cycle.
- Cross-functional teams where product managers review outputs alongside engineers.
- Companies that need SOC 2 coverage without an enterprise contract.
Pricing
The Starter plan is free with 1 GB of processed data and 10,000 scored outputs per month. Pro is $249/month and adds custom dashboards and environment support. Enterprise pricing is custom and requires a quote.
2. Langfuse
Langfuse was acquired by ClickHouse in January 2026. It's what teams deploy when they can't send conversation data outside their own servers.
The MIT license covers everything. Self-hosting costs nothing, and no feature is locked behind a paid tier.
Over 40,000 builders run it in production. Some are solo developers testing early prototypes. Others are enterprise teams under legal constraints that rule out third-party cloud providers entirely.
"Langfuse powers our LLM observability. Without Langfuse, our AI agent would not be best-in-class." — Alex Danilowicz, Product Hunt
Key Features
- Distributed tracing records agent calls, sessions, token counts, and costs across all major LLM frameworks without extra setup.
- Prompt management covers version control, composability, server and client-side caching, a playground, and release management.
- LLM-as-judge evaluations score outputs via pre-built evaluators or custom scoring, with human annotation queues and user feedback tracking.
- Transparent overage pricing drops from $8 to $6 per 100k units at scale, so you know what you'll pay before signing anything.
- Self-hosted Enterprise tier adds project-level access controls, audit logs, SCIM-based user provisioning, and SOC 2 Type II and ISO 27001 certifications.
Pros
✅ Every core feature ships in the open-source version, including tracing, evaluations, and prompt management.
✅ Core plan is $29/month flat for unlimited users.
✅ Pro at $199/month includes SOC 2 Type II, ISO 27001, and a HIPAA BAA without an enterprise contract.
Cons
❌ The API filter for listing traces is broken: it ignores your parameters and returns everything, which makes any automated trace query unreliable.
❌ High-volume self-hosted deployments on S3 exhaust available file descriptors quickly. When that happens, the server stops writing data silently.
❌ Evaluation scores don't block deployments. Catching regressions before they ship requires tooling outside Langfuse.
Best For
- Teams under legal or contractual restrictions on where conversation data can travel.
- Growing teams that need more than two seats without paying per person.
- Companies that need SOC 2 or HIPAA but can't justify an enterprise sales conversation.
Pricing
Langfuse offers multiple pricing plans:
- The Hobby plan is free, and there's no card needed to get started.
- Core is $29/month for unlimited users.
- Pro runs $199/month and covers compliance.
- The Enterprise plan starts at $2,499/month with negotiable throughput and a dedicated engineer assigned to your account.
3. LangSmith
LangSmith is what you get when the team that built LangChain also builds the observability layer.
Every LangChain and LangGraph call captures automatically with a single environment variable. No SDK instrumentation, no manual setup. Engineers outside that ecosystem can still connect via OpenTelemetry, but the friction-free experience disappears once you leave the native stack.
"The Python SDK is handy and we've automated LangSmith evals as part of CI/CD on GitHub to spot regressions." — Hannah Craighead, Product Hunt
Key Features
- Automatic capture for LangChain and LangGraph via one environment variable, covering agents, tool calls, and retrieval steps without additional code.
- Online and offline evaluations that score production runs in real time or batch experiments against datasets, both from the same interface.
- Prompt Hub and Playground for version-controlled prompt management with a live testing environment and iterative improvement via Canvas.
- Insights (beta) automatically clusters runs to surface usage patterns, failure modes, and common agent behaviors across workspaces.
- LangSmith Deployment provides managed infrastructure for LangGraph agents with one-click deployment, cron scheduling, and horizontal scaling on the production tier.
Pros
✅ The native stack integration means LangChain and LangGraph calls appear in the dashboard before a developer writes a single line of instrumentation code.
✅ Extended retention goes up to 400 days on Plus, well above most competitors at this price point.
✅ The Startup program offers discounted rates for seed-stage companies under $10M in funding, with no enterprise contract required.
Cons
❌ Perplexity cost tracking is inaccurate by an order of magnitude. Search query costs never appear in runs.
❌ One agent running with tool calls generates multiple billable entries. The free tier disappears faster than expected.
❌ Self-hosting and HIPAA coverage are both covered under an enterprise contract. Neither is available without a sales conversation.
Best For
- Engineering teams whose entire stack runs on LangChain or LangGraph.
- Companies that need long data retention without signing an enterprise deal.
- Early-stage startups that qualify for the seed program and want managed deployment included.
Pricing
LangSmith offers pricing plans where you can pay for what you actually use.
The developer plan starts free for one seat with 5,000 runs per month. Plus starts at $39/seat/month with 10,000 base runs included. Then both plans become pay-as-you-go. The Enterprise plan is custom and requires a quote.
4. W&B Weave
Weave is what teams reach for when they already live in the Weights & Biases ecosystem and need LLM observability without adding another vendor.
The platform covers tracing, evaluation, production monitoring, and cost tracking across any LLM framework. PII redaction is included in the free plan, which most competing tools reserve for paid tiers.
Over a million AI engineers use the broader W&B platform across startups and Fortune 500 companies.
"It is highly and well integrated with libraries I am using, like PyTorch Lightning." — Amir Masoud N., G2
Key Features
- Framework-agnostic tracing using simple function decorators in Python or TypeScript, covering the full call chain beyond just LLM requests.
- LLM-as-judge evaluations scoring outputs against datasets and tracking regressions over time, with automated triggers in CI/CD pipelines.
- Automatic cost tracking calculates spend per call by model, with custom pricing support for fine-tuned models.
- Built-in inference API giving Pro users access to open-source models, including Gemma, Nemotron, and Qwen without a separate provider account.
- Wooly agent for asking natural-language questions about engineering output, AI tool adoption, and agent performance across the organization.
Pros
✅ PII redaction is available from day one, without upgrading, which is rare at this price point.
✅ Students, professors, and postdoctoral researchers get a full Pro-equivalent license free, with 200 GB storage and up to 100 seats.
✅ Works with OpenAI Agents SDK, LangChain, CrewAI, LlamaIndex, Dify, and MCP, so switching from another tool usually means changing a few lines, not rebuilding your setup.
Cons
❌ Teams running on Google Cloud Functions get no trace data at all. Weave drops calls silently in that environment
❌ Adding Weave to CrewAI agents causes them to freeze on startup and never complete a run
❌ LLM scorer overhead is counted in evaluation totals, so reported costs and latencies in dashboards read higher than actual application performance
Best For
- Teams already using W&B for model training who want observability on the same platform.
- Projects handling sensitive data that need PII redaction on a free plan.
- Researchers and academics who qualify for the Pro-equivalent license at no cost.
Pricing
The Free plan includes 1 GB monthly ingestion and PII redaction. Pro starts at $60/month (billed monthly) for teams under 50 employees. Enterprise is better for companies that need security and compliance, and the custom pricing requires a quote.
5. Fiddler AI

Fiddler is the only tool on this list that covers both classical ML models and LLM agents in one place.
It started in ML monitoring and expanded into generative AI. That means compliance and engineering teams get model performance tracking and LLM safety in one contract.
Gartner also covers it in their Market Guide for AI Evaluation and Observability Platforms, which helps with internal procurement approvals.
"Fiddler's monitoring capabilities, especially around LLMs, are extremely powerful. Its model explanation feature is simply awesome." — Ibrahim D., G2
Key Features
- Sub-100ms safety checks using proprietary Trust Models that flag hallucinations, PII, prompt injection, and jailbreak attempts without an external LLM call.
- Cross-system root cause analysis that links agentic LLM behavior to predictive model performance on a single dashboard.
- Bring your own judge lets teams plug in any custom evaluator or LLM scorer alongside Fiddler's built-in metrics.
- Agentic hierarchy tracking captures the full execution context of compound AI systems, including decision lineage across agent calls.
- Explainable AI suite with SHAP-based feature importance, gradient explanations, and counterfactual analysis for tabular, text, and image data.
Pros
✅ Safety checks run in under 100ms on the free plan. LLM-as-judge alternatives add seconds and extra API costs per call.
✅ Developer plan charges $0.002 per trace with no platform fee. 10,000 traces a month costs only $20.
✅ RBAC and SSO are available on the Developer plan, not locked behind a sales conversation as they are on most tools here.
Cons
❌ Initial setup is consistently flagged as difficult in user reviews, particularly for teams without prior ML operations experience.
❌ Volume pricing above the Developer tier is fully opaque. There's no public calculator, which makes budget forecasting harder than with Langfuse or LangSmith.
❌ Reviews are limited on G2 and Capterra as of April 2026. Production-scale performance is hard to verify independently.
Best For
- Regulated industries that need drift detection and LLM monitoring under one contract.
- Security-focused teams that need fast safety checks without adding inference costs per request.
- Procurement processes that require Gartner or analyst recognition before approving a vendor.
Pricing
The Free plan covers core safety checks. Developer charges $0.002 per trace with no monthly minimum. Enterprise requires you to contact sales for a quote.
6. Galileo
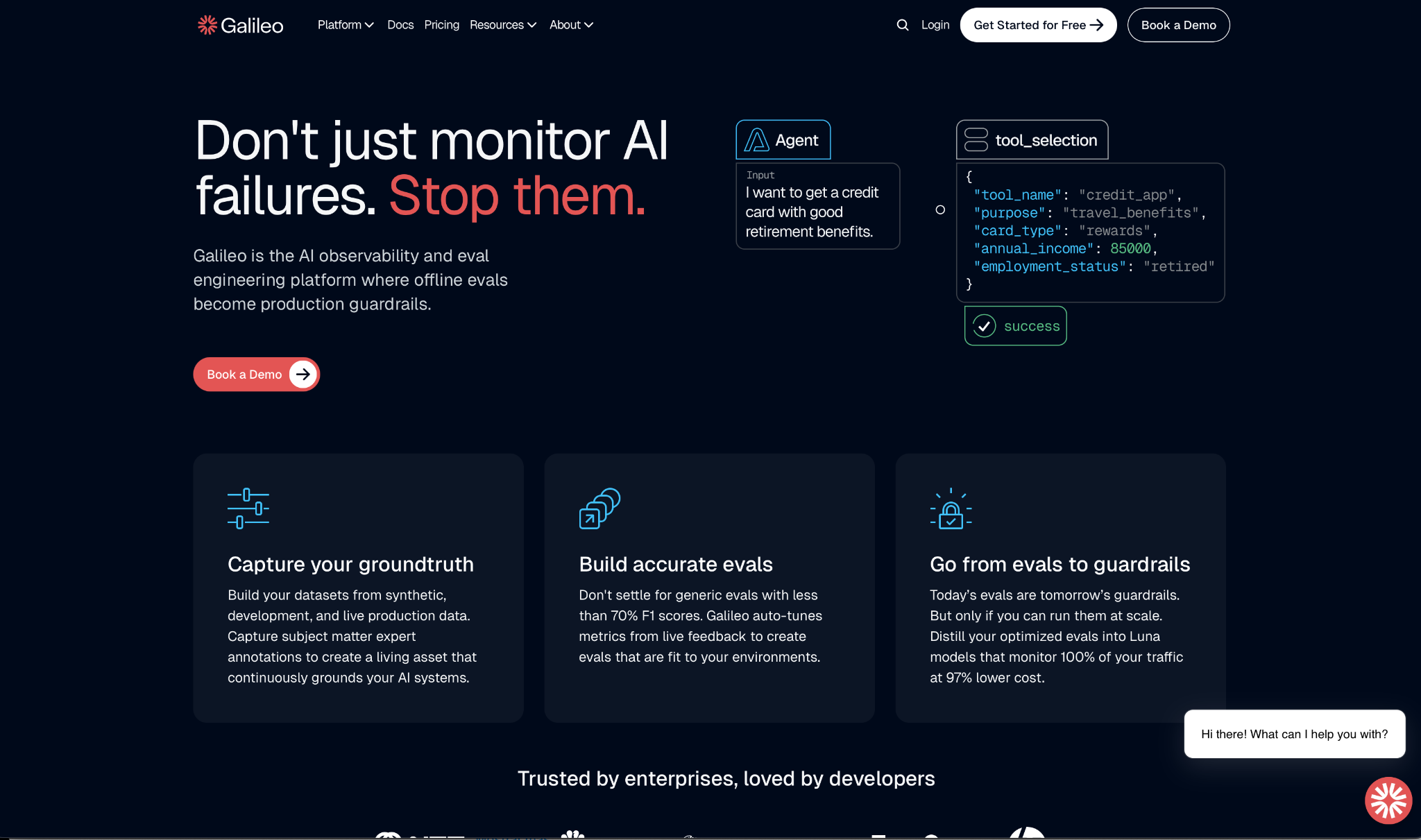
Galileo closes the gap between testing your AI before launch and watching it in production.
The same quality checks you run during development become the rules that block bad outputs once users are on the line. Twilio, Comcast, and HP use it in production.
The Luna models behind the evaluation layer run at sub-200ms latency, which makes monitoring every call practical instead of sampling.
"Its intuitive interface and real-time collaboration features boost productivity, though there's a slight learning curve for more complex projects." — Arun Kumar S., G2
Key Features
- Luna model distillation turns expensive LLM judge calls into compact models that run at 97% lower cost, making it practical to check every production call instead of sampling.
- Eval-to-guardrail pipeline converts test results into live production controls, covering hallucinations, jailbreaks, and PII with no separate setup.
- 20+ pre-built evaluators for RAG quality, agent tool selection, safety, and security, all available on the free plan.
- Failure mode clustering groups similar errors and surfaces root causes automatically, reducing time spent reviewing individual bad outputs.
- Agent tracing captures the full decision path across multi-step completions, tool calls, and retrieval operations on all plans.
Pros
✅ Free plan includes unlimited users and custom evaluations, more generous than Braintrust or LangSmith at this price point.
✅ Luna-distilled models let teams check every call in production without paying for a large LLM inference per safety check.
✅ Connects to LangChain, LangGraph, CrewAI, OpenAI, Anthropic, Azure, Ollama, and OpenTelemetry without rewriting existing code.
Cons
❌ Support for external pre-trained models is limited. Teams using custom base models not in Galileo's native list will hit compatibility gaps.
❌ Processing datasets in the millions is slow and needs manual tuning, which makes large-scale batch workflows impractical.
❌ Pro plan trace overage pricing isn't published. You need to contact sales to know what you'll pay past 50,000 traces per month.
Best For
- Teams that want development quality checks to carry over into production without writing extra code.
- Companies monitoring high-traffic agents where running a large model per safety check is too expensive.
- Regulated industries that need VPC or on-premises deployment with engineering support included.
Pricing
Galileo offers a pricing plan whether you're just getting started or need enterprise-grade capabilities. Here's what they include:
- The Free plan covers 5,000 traces per month with unlimited users and custom evals.
- Pro starts at $100/month when billed annually or $150/month when billed monthly, and includes 50,000 traces.
- Enterprise pricing is custom and requires you to book a demo to get started.
7. Opik by Comet
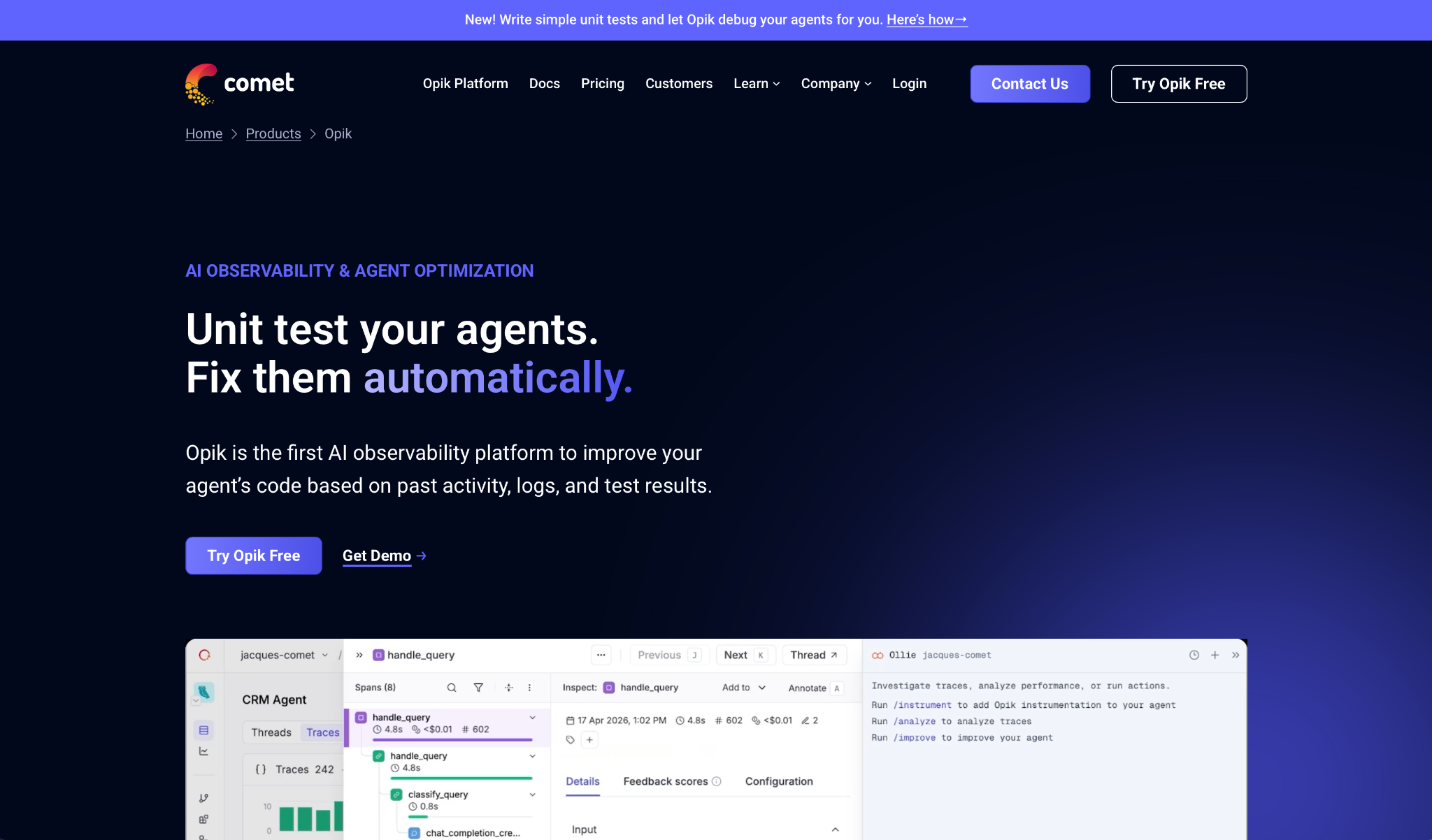
Opik is open-source, free to self-host, and ships with a coding assistant that reads your traces and writes fixes directly to your codebase.
It runs on the same infrastructure as Comet's ML platform and is used by over 150,000 developers. The Apache 2.0 license covers everything, including tracing, evaluations, datasets, and prompt optimization.
"Strong for tracing and understanding what happened during a run. Opik felt decent for prompt tracking." — Verified User, Reddit
Key Features
- Ollie coding assistant analyzes trace patterns, identifies what's failing, and pushes fixes to your codebase with version control included.
- 7 prompt optimization algorithms, including MIPROv2 and Bootstrap, are available without an enterprise plan.
- Span hierarchy logging captures tool calls, retrieval steps, and model parameters across multi-step workflows in a navigable tree.
- Online evaluation rules score production traffic in real time and alert when interactions fail defined criteria, with guardrails blocking PII exposure.
- Native pytest integration for unit-testing LLM outputs, a workflow most competing platforms don't support directly.
Pros
✅ The self-hosted version has no feature gating or span limits, covering tracing, evaluations, datasets, and prompt optimization at zero cost.
✅ Cloud free plan includes unlimited team members with LLM-as-judge metrics, no seat limits, and no credit card required.
✅ Pro is $19/month with overage at $5 per 100K additional spans, one of the lowest entry points on this list.
Cons
❌ Vertex AI token tracking fails silently when usage data is incomplete, so Gemini call costs never appear in dashboards.
❌ Complex multi-agent workflows using nested ADK callbacks trigger infinite recursion, which crashes the setup before completing a run.
❌ Fine-tuning is outside the platform's scope. Prompt optimization is the end of the road here.
Best For
- Developer teams that want observability and automated code fixes without switching tools.
- Companies that need unlimited self-hosting with no licensing cost and full feature access.
- Growing teams looking for the lowest paid entry point with predictable overage pricing.
Pricing
Opik has flexible pricing plans for all teams:
- There are two free options: Open Source, available for download on GitHub, and Free Cloud, which covers up to 10 team members.
- Pro is $19/month with up to 50 team members and 100,000 spans, then pay-as-you-go overages.
- Enterprise pricing is custom, so you need to contact sales.
How to Evaluate Arize AI Alternatives
Knowing which questions to ask before you choose saves more time than any feature comparison.
Here's where to start:
- Where does your data need to live? If data residency is a hard requirement, your shortlist is limited to options with full parity in self-hosted mode. Check what gets restricted in the open-source version before you commit.
- What stage of the lifecycle matters most? Some options focus on pre-production evaluation and CI/CD gating. Others focus on production monitoring. Start with where your team is losing the most time.
- Who needs access? If product managers and domain experts need to review outputs without engineering support, the interface matters as much as the capabilities.
- How does pricing scale with actual usage? Billing models based on traces, seats, or flat rates produce very different cost curves as volume increases. Factor in retries and agent tool calls, not just successful end-user requests.
- What frameworks are you running? Deep integrations are only an advantage if that's your infrastructure. For teams using several providers, OpenTelemetry-native options reduce switching costs across the board.
- What happens when evaluation scores drop? Some options surface the problem. Others block the deployment automatically. The second scenario matters when your organization ships several times a day.
Are You Building a Voice or Conversational AI Agent?
The seven platforms above handle what happens inside your LLM pipeline. None of them test how your agent performs when real people push it off-script across thousands of conversations. That's where Cekura fits.
Cekura runs on top of whichever provider you choose and closes that gap. Here's what it offers:
- Testing at scale: Thousands of simulated calls run before go-live, catching the edge cases that only surface when real people push your agent off-script.
- Automated red teaming: Stress-tests your agent against adversarial inputs, bias, and unexpected caller behavior before any of it reaches a real customer.
- Latency tracking: Cekura pinpoints where slowdowns originate in the pipeline so you know exactly what to fix after each provider swap or prompt update.
- CI/CD integration: Every time you update a prompt or swap a provider, Cekura runs your full test suite before anything goes live.
- Custom evaluation: Score every call on accuracy, missed intents, and incorrect responses using predefined metrics or your own criteria.
Native integrations work out of the box for Retell, VAPI, ElevenLabs, LiveKit, Pipecat, Bland, and more. You add a testing and monitoring layer on top of what you already have. Nothing gets rebuilt.
Cekura is also SOC 2-, HIPAA-, and GDPR-compliant. Transcript redaction, role-based access, and audit trails are all included.
Most issues only show up when real people are on the line. Schedule a demo with Cekura to see how you can fix those issues before your users spot them.
Frequently Asked Questions
What Is the Best Free Alternative to Arize AI?
Langfuse is the best free alternative to Arize AI for teams that need full feature access at no cost. The open-source MIT license covers tracing, evaluations, and prompt management with unlimited spans and no feature gating.
What Is the Difference Between Arize AI and Langfuse?
The main difference between Arize AI and Langfuse lies in their origins. Arize started as an ML monitoring platform and expanded into LLMs, while Langfuse was built specifically for LLM engineering teams with full open-source self-hosting included.
Does Arize AI Work With LangChain?
Yes, Arize AI works with LangChain through OpenTelemetry-based instrumentation. LangSmith offers deeper native integration built by the same team, including zero-config tracing with a single environment variable.
What Is the Difference Between Arize Phoenix and Arize AX?
Arize Phoenix is the free open-source version for local development and tracing. Arize AX is the commercial platform that adds production monitoring, compliance certifications, and team collaboration features, with pricing starting around $50,000 per year.