
Voice AI for agent orchestration roundups lead with latency benchmarks and pricing tables. I spent time inside each platform building real call flows, checking how the orchestration layer handles interruptions, tool calls, and multi-turn context. None of them made it into this list without that test.
7 Best Voice AI Tools for Agent Orchestration: Quick Comparison
| 💻 Tool | ⚡ Strengths | 🎯 Best For | 💰 Starting Price |
|---|---|---|---|
| VAPI | API-native, BYOK, dual no-code + API access | Developer teams building custom voice pipelines | $0.05/minute platform fee and provider costs |
| Retell AI | ~600ms latency, drag-and-drop + API, built-in QA | Contact center and sales call automation | $0.07/minute; pay-as-you-go, billed monthly |
| LiveKit | Open-source, WebRTC-first, multimodal, self-host option | If you need full infra control across voice and video | Free (Build plan, no credit card required); Ship from $50/month |
| Pipecat | Vendor-neutral Python framework, 80+ provider integrations | Developers who want complete pipeline ownership | $0.01/minute active hosting (agent-1x profile); usage-based, billed monthly |
| Telnyx | Carrier-owned network, built-in STT/TTS/LLM, no third-party telephony and carrier-grade quality | If you prioritize cost predictability | $0.05/minute Conversational AI base rate; pay-as-you-go, billed monthly |
| SigmaMind | No-code + API, omnichannel (voice/chat/email), model-agnostic, MCP server | If you're building production agents across multiple channels | $0.04/minute platform fee; pay-as-you-go, billed monthly |
| Rapida | Open-source (GPL-2.0), self-hosted or managed, zero platform markup | Agencies and enterprises that need full data ownership | $500/month (Scale); Enterprise custom |
How I Researched and Tested These Voice AI Orchestration Tools
I tested each platform by building a complete inbound call flow. That meant a healthcare appointment booking agent with interruption handling, tool calls to an external calendar API, and a warm transfer trigger. Where a free tier existed, I ran it.
Where it didn't, I worked through the documentation, sandbox environments, and developer changelogs to verify claims.
- Orchestration depth: How the platform manages STT-to-LLM-to-TTS sequencing under real conditions, including mid-sentence interruptions, overlapping speech, and tool call latency. Platforms that abstract this cleanly scored higher.
- Developer experience: Whether the API surface is consistent, the docs are current, and a solo engineer can go from zero to a working agent in under a day. I paid attention to how much glue code each platform required.
- Telephony and transport: Whether telephony is native or delegated to a third party like Twilio, and what that means for latency, billing complexity, and production reliability.
- Model flexibility: Whether you can swap STT, LLM, and TTS providers independently or are locked into the platform's defaults. This matters the moment your preferred model changes or a better option ships.
- Pricing transparency: Whether the number on the pricing page reflects what you pay in production. Several platforms separate platform fees from provider costs in ways that compound quickly at scale.
- Production readiness: Compliance posture, concurrency handling, observability tooling, and how teams are using these platforms in live deployments today.
Between hands-on testing and documentation review, I came away with a sharper read on each platform's suitability for voice AI agent orchestration than benchmarks alone would give.
1. VAPI: Best for Full-Stack Voice AI Agent Orchestration
What it does: VAPI is a voice AI for agent orchestration tool that connects your STT, LLM, and TTS providers into a single real-time voice pipeline. It handles the routing, streaming, and turn-by-turn conversation logic between them.
Best for: Developer teams who need full provider flexibility and want to go from prompt to a working voice agent without standing up their own infrastructure.
I ran a multi-turn appointment booking agent on VAPI and swapped the transcription provider mid-project in under five minutes with no latency regression. The Flow Studio lets you map conversation logic visually, then drop into the API for anything the canvas can't cover.
That flexibility comes with a billing model to match. You're tracking charges across the platform, STT, LLM, TTS, and telephony simultaneously. HIPAA compliance is a $2,000/month add-on that doesn't come with any plan by default.
Key Features
- Modular STT/LLM/TTS stack: Swap any provider independently, or bring your own API keys and pay model costs at cost with $0 VAPI markup.
- The Flow Studio covers visual conversation mapping for multi-step flows. Drop into the API for anything the canvas can't handle.
- BYOK support: Connect your own OpenAI, Anthropic, Deepgram, ElevenLabs, or Cartesia keys and VAPI passes provider costs through with no markup.
- VAPI Monitoring tracks latency breakdowns per active agent across all calls in real time.
- Enterprise compliance: SOC 2, HIPAA, and PCI available on Scale plans, with SSO and RBAC.
Pros and Cons
Pros:
✅ True provider modularity with no lock-in on any layer of the stack
✅ 1M+ developer community with extensive documentation and ready-to-use integration patterns
✅ Enterprise plans include contractual uptime guarantees with reserved capacity and dedicated account support
Cons:
❌ Latency can be inconsistent in production, with spikes to 4-5 seconds reported under high call volume
❌ Dashboard assumes developer-level knowledge, so non-technical users will hit friction fast
What Users Say
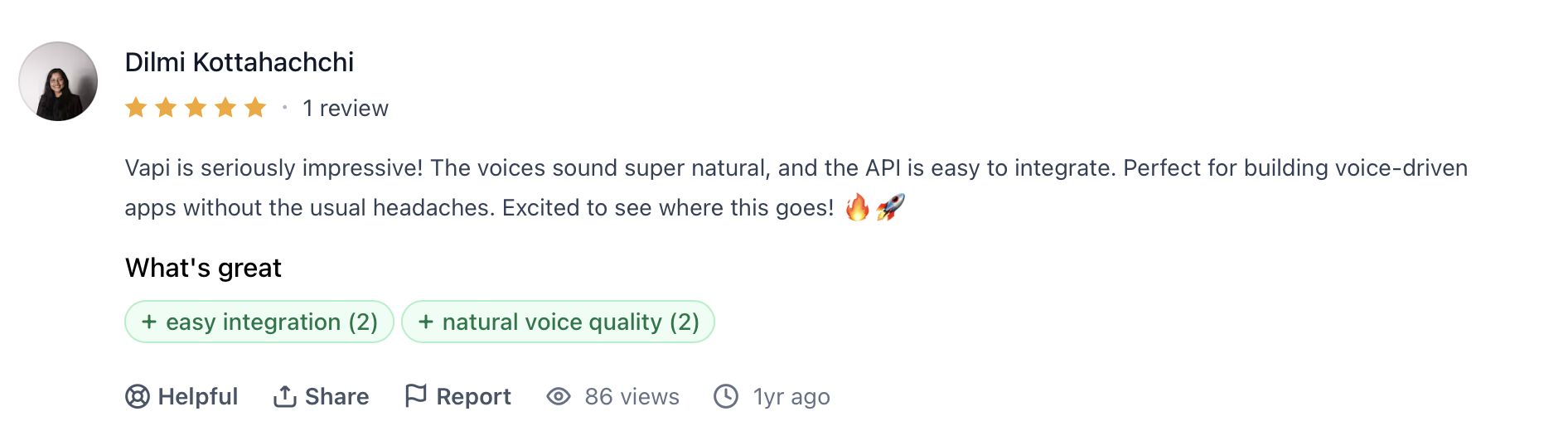
"VAPI is seriously impressive! The voices sound super natural, and the API is easy to integrate. Perfect for building voice-driven apps without the usual headaches." — Dilmi Kottahachchi, G2
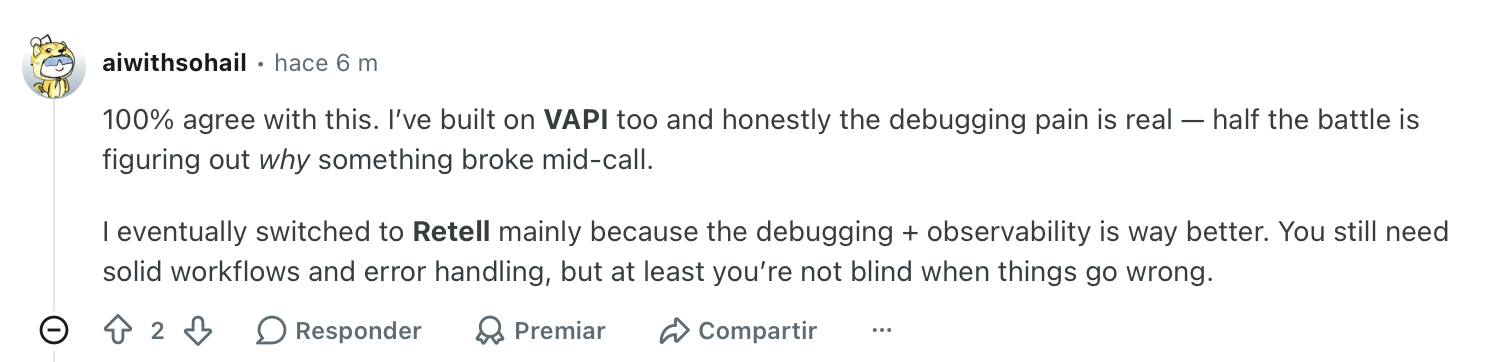
"I've built on VAPI too, and honestly, the debugging pain is real. Half the battle is figuring out why something broke mid-call." — Verified User, Reddit
Pricing
The Build plan starts at $0.05/min as a VAPI hosting fee, with STT, LLM, and TTS provider costs billed on top at cost. Bring your own API keys, and the VAPI markup drops to $0.
Bottom Line
VAPI is the pick when provider flexibility and orchestration depth come first. If you need HIPAA compliance, the $2,000/month add-on is a fixed cost to plan for from day one.
2. Retell AI: Best for Managed Full-Stack Phone Agent Deployment
What it does: Retell AI is a full-stack, managed voice AI for agent orchestration platform that handles the entire call pipeline, including STT, LLM, TTS, telephony, and orchestration, letting teams go from signup to a live phone agent on Retell's infrastructure.
Best for: Engineering teams that need to ship phone agents to production fast, with native telephony, omnichannel support, and enterprise compliance out of the box.
From a cold account, a live inbound agent was taking calls in under 15 minutes using the drag-and-drop flow builder, with real-time function calling for appointment booking and a warm transfer trigger configured in the same session. Retell's turn-taking model handled interruptions cleanly throughout.
That speed comes with a provider tradeoff. Retell's STT selection defaults to Azure and Deepgram natively, and teams that need a specific TTS voice outside Retell's catalog will need to check whether BYOK covers their combination.
Key Features
- Proprietary Voice AI Orchestration: Built-in turn-taking model with ~600ms latency, trained on real performance data and tuned for interruption and barge-in handling.
- The Agentic Framework covers drag-and-drop call flow building with guardrails, real-time function calling, and preset functions for appointment booking, payments, and CRM updates.
- Streaming Knowledge Base: Crawls and re-syncs your website content every 24 hours to give agents accurate answers during live calls without manual updates.
- Omnichannel: Voice, SMS, and chat on the same agent framework, deployable via Twilio, SIP, branded caller ID, or Retell's web SDK.
- HIPAA, SOC 2 Type I and II, and GDPR compliance with BAA available at no additional cost on any plan.
Pros and Cons
Pros:
✅ Full platform access on every plan with no feature gating and no platform fees
✅ Compliance with BAA available at no additional cost on any plan
✅ 4.8/5 on G2 across 2,400+ reviews, with consistent praise for setup speed and call quality
Cons:
❌ Provider selection is narrower than VAPI by default. Teams that need a specific STT provider outside Azure and Deepgram, or a TTS voice outside Retell's catalog, will hit friction even with BYOK
❌ Campaign management, analytics depth, and prompt version control are the most common gaps users mention at enterprise scale
What Users Say
"It feels polished and easy to work with, especially thanks to features like batch calling and integrations with Twilio and Telnyx." — Rishav K., G2
"Retell AI has largely supported our conversations, but advanced settings and configurations need individuals with experience concerning conversational AI." — Luciana S., G2
Pricing
Pay-as-you-go starts at $0.07/min for AI Voice Agents, with $10 in free credits on signup. Enterprise pricing on request.
Bottom Line
Retell AI gets you from zero to a live phone agent faster than any other managed platform on this list. HIPAA and SOC 2 compliance with no add-on fees gives healthcare and regulated teams one less thing to negotiate.
3. LiveKit: Best for Open-Source Voice AI Infrastructure
What it does: LiveKit is an open-source, WebRTC-first voice AI for agent orchestration tool for building real-time voice and video agents, with a full Agents framework that manages STT-to-LLM-to-TTS pipelines, turn detection, and multi-agent handoffs.
Best for: Developer teams that need full infrastructure control, provider freedom, and the option to self-host, with no lock-in on any layer of the stack.
Building a multi-turn support agent on LiveKit's Agents framework required more setup than managed platforms. What came back was full control over every pipeline node, native telephony via SIP without a Twilio bridge, and the ability to swap Deepgram for AssemblyAI mid-pipeline with two lines of code.
The supervisor pattern for multi-agent handoffs worked cleanly across three agent types in a single session. Teams running lower volumes will find that configuration and maintenance time erodes any cost difference.
Key Features
- LiveKit Agents Framework: Open-source SDK (Apache 2.0) for building STT-LLM-TTS pipelines with worker orchestration, load balancing, and Kubernetes compatibility. The LiveKit turn detector is an open-weight plugin running CPU inference in under 25ms across 13 languages including English, Spanish, French, German, and Japanese.
- Multi-agent Handoffs: Supervisor pattern for routing callers across multiple specialist agents within a single session, passing conversation context at handoff.
- Native Telephony: First-party SIP trunking and phone numbers with inbound and outbound calling, no Twilio bridge required.
- LiveKit Inference is a managed inference layer for running STT, TTS, and LLM models directly on LiveKit Cloud with no external API keys needed.
Pros and Cons
Pros:
✅ Full open-source codebase (Apache 2.0) with self-host or managed cloud on the same APIs and SDKs
✅ STT, LLM, and TTS providers are all swappable independently with no lock-in at any layer
✅ Native SIP telephony and phone numbers without a third-party telephony provider
Cons:
❌ More infrastructure setup and maintenance than managed platforms. Teams without real-time system experience will face a steeper ramp
❌ Enterprise plan pricing is a friction point for mid-market teams, with concurrency limits on lower tiers
What Users Say
"Their Inference Service and Agent Plugin made it straightforward for developers to plug Realtime TTS into live audio pipelines." — Andreas Assad Kottner, Product Hunt
"Concurrency is limited to 5 users in the paid version which is not helpful to the business, and their enterprise plan is not affordable." — Viren S., G2
Pricing
Build plan is free with no credit card required. Ship starts at $50/month. Scale starts at $500/month. All plans are billed monthly with usage-based metering on top.
Bottom Line
LiveKit gives you full stack control with no managed-platform ceiling, as long as your team can own the infrastructure. Retell AI and VAPI will get you to a working call faster if deployment speed matters more than long-term cost at scale.
4. Pipecat: Best for Python-Native Voice Pipeline Ownership
What it does: Pipecat is an open-source Python framework for building real-time voice and multimodal AI agents. This voice AI for agent orchestration tool lets you assemble your own STT-LLM-TTS pipeline from composable processors with full visibility into every stage.
Best for: Python developers who want complete control over each processing step, vendor freedom across 100+ services, and the option to deploy on Pipecat Cloud or any infrastructure that runs Python.
Assembling a customer intake agent with Pipecat meant defining the pipeline explicitly, with frame processors in sequence and each service dropped in via a single import. Swapping Deepgram for AssemblyAI for STT took one line.
One constraint comes with the territory. Pipecat runs Python-only on the server side, so teams working in Go, Node, or Java will need to maintain a Python service boundary for their agent logic, which adds an architectural seam.
Key Features
- Pipeline Architecture uses frame-based processing where audio, text, and video move through composable processors stage by stage, with full visibility and control at each point.
- Smart Turn Detection: Open-source model running CPU inference in under 25ms, with local VAD and phrase endpointing for natural interruption handling without external API calls.
- Pipecat Flows: Structured conversation state management for building defined conversational paths with branching logic and state transitions.
- Single-package installs for STT (Deepgram, AssemblyAI, Azure, Whisper), LLM (OpenAI, Anthropic, Gemini, Groq), and TTS (Cartesia, ElevenLabs, Azure) with no lock-in across all of them.
- Pipecat Cloud: Managed hosting on Daily's global infrastructure with autoscaling, native PSTN/SIP telephony, Krisp noise cancellation, and HIPAA/GDPR compliance.
Pros and Cons
Pros:
✅ Pipeline transparency: each processing stage is inspectable and replaceable without touching adjacent stages
✅ 12,700+ GitHub stars and active Discord community maintained by the Daily engineering team
✅ NVIDIA, AWS, and RTVI standard partnerships listed on pipecat.ai
Cons:
❌ Python-only server framework. Teams working in other languages need a dedicated Python service for agent logic
❌ More initial configuration than managed platforms. Latency tuning requires explicit pipeline design rather than defaults
What Users Say
"I highly recommend using Pipecat or Livekit orchestration frameworks for any voice/vision AI agent." — Verified User, Reddit
"I'm using dailybots (with daily hosted pipecat). The only negative for any of the transport providers is per-minute vs per-second rates (daily is .02 per min)." — Verified User, Reddit
Pricing
Pipecat framework is free and open-source (BSD-2-Clause). Pipecat Cloud hosting starts at $0.01/min for the agent-1x profile (0.5 vCPU, 1 GB), billed monthly with usage-based metering. PSTN telephony starts at $0.018/minute.
Bottom Line
Pipecat gives Python developers visibility into every processing stage and the freedom to swap services without disrupting upstream stages. If you'd rather skip pipeline design and ship faster you will land on Retell AI or VAPI instead.
5. Telnyx: Best for Carrier-Owned Voice AI Infrastructure
What it does: Telnyx is a licensed voice AI for agent orchestration tool that owns its own global IP backbone, co-located GPU infrastructure, and telephony stack, delivering STT, TTS, LLM orchestration, and PSTN connectivity from a single platform without routing through third-party providers.
Best for: Engineering teams that need predictable latency, clear all-in pricing, and carrier-grade call quality without assembling and billing separate telephony, STT, TTS, and LLM vendors.
Tracing a call through Telnyx shows the difference directly. On modular platforms, STT, LLM, TTS, and telephony come from separate providers, and each audio byte hops across multiple external services before delivery.
Telnyx runs those components on its own private backbone with GPUs co-located at the same PoPs handling the carrier layer. If you have strong opinions about a specific LLM version or TTS voice outside Telnyx's catalog you'll need to use BYOK, which adds a billing layer that offsets that simplicity.
Key Features
- Private IP backbone with co-located GPUs: 18 global PoPs with AI inference running on the same infrastructure as the carrier layer, delivering sub-200ms round-trip time without routing across public cloud providers.
- Multi-agent handoffs route callers between specialized agents mid-call, with context carried across each transition.
- AI Missions: Sends agents on multi-step autonomous workflows covering appointment booking, document verification, and record updates without human intervention.
- Voice Design Lab: Custom voice cloning and brand voice creation from scratch, with HD codecs and noise suppression across calls.
- Full-stack observability covers latency breakdowns per pipeline stage, transcript playback, and call records from start to completion, all accessible in one place.
Pros and Cons
Pros:
✅ Single vendor for telephony, STT, TTS, LLM orchestration, and global numbers across 140+ countries
✅ STIR/SHAKEN A-level attestation means calls are marked as trusted, not spam
✅ SOC 2 Type II, HIPAA, PCI DSS, ISO 27001, and GDPR compliance included on the platform
Cons:
❌ Number provisioning in certain regions can involve delays and support friction
❌ Account onboarding involves a human review step, which adds setup time compared to self-serve platforms
What Users Say
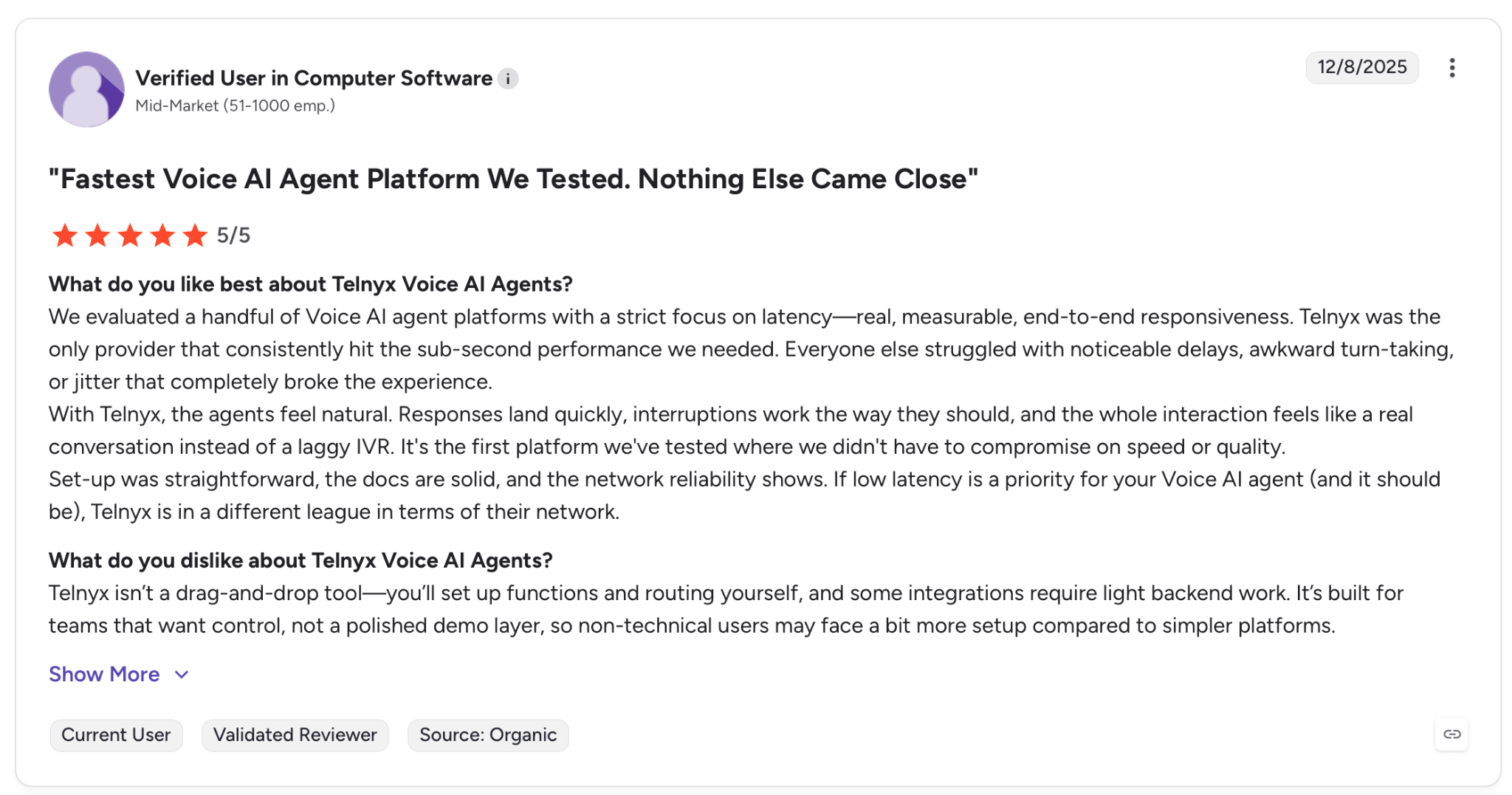
"We evaluated a handful of Voice AI agent platforms with a strict focus on latency - real, measurable, end-to-end responsiveness. Telnyx was the only provider that consistently hit the sub-second performance we needed." — Verified User, G2
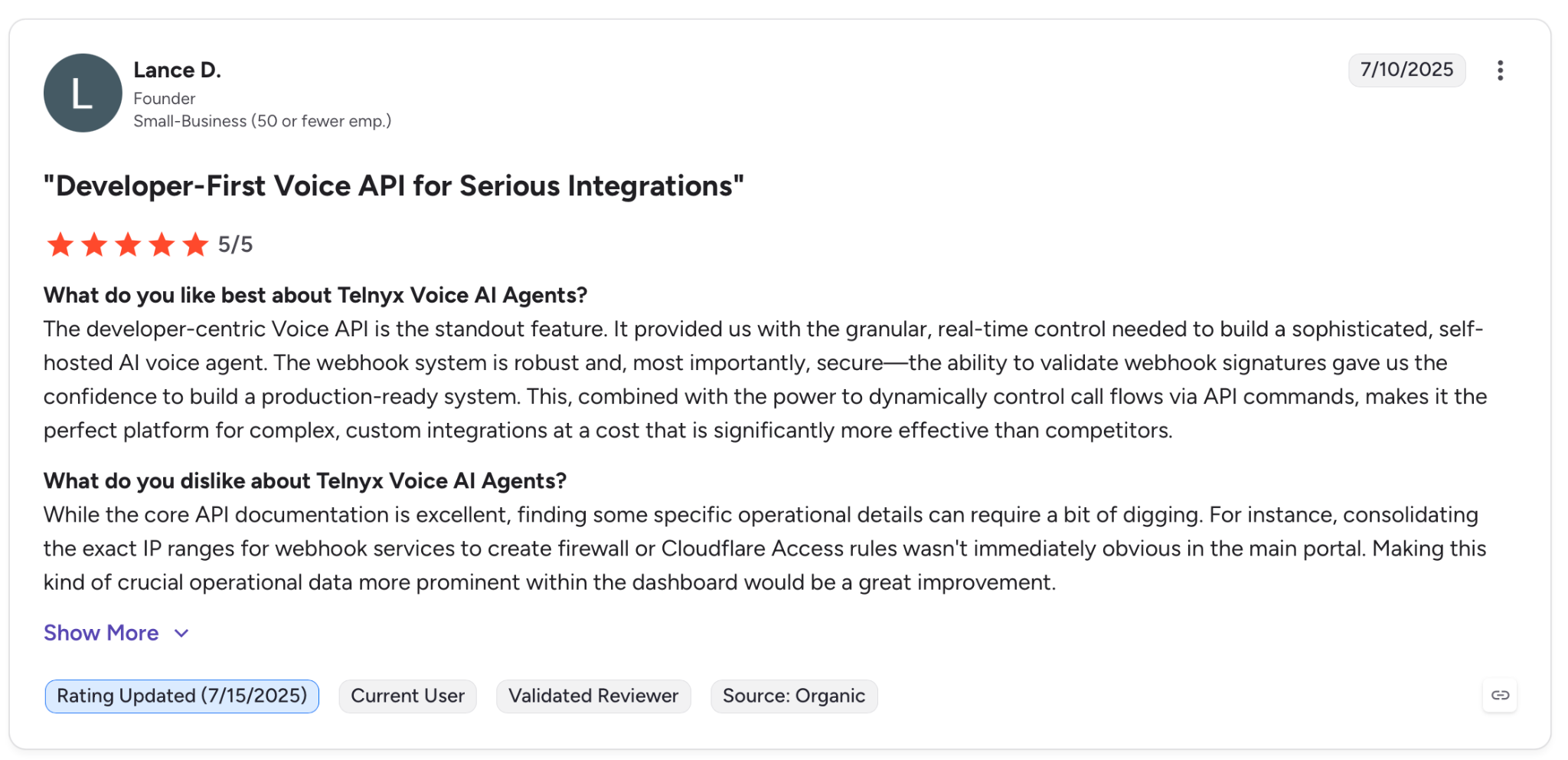
"While the core API documentation is excellent, finding some specific operational details can require a bit of digging." — Lance D., G2
Pricing
Conversational AI starts at $0.05/min as the base orchestration rate, with telephony, STT, and TTS billed on top at usage-based rates. Pay-as-you-go, billed monthly. Volume-based contracts available.
Bottom Line
If single-vendor billing and carrier-grade call quality are the priority, Telnyx is where this list ends for you. Verify availability before committing if your number coverage needs fall in regions where Telnyx's reach is thin.
6. SigmaMind AI: Best for Omnichannel Voice Agent Orchestration
What it does: SigmaMind AI is a YC-backed conversational AI platform that runs the same agent logic across voice, chat, and email from a single orchestration layer. This voice AI for agent orchestration tool keeps conversation state and business rules in one place regardless of which channel the customer uses.
Best for: Mid-market and enterprise teams that need production-grade voice with a no-code builder, model-agnostic STT/LLM/TTS, and the option to extend functionality through APIs and an MCP server.
Switching an appointment booking agent from voice to chat kept the full conversation context and branching logic intact without any reconfiguration, which is the single control plane in practice.
The Playground let me simulate channel transitions before touching production, a testing capability I didn't find in the other voice-first platforms on this list.
Where the platform shows its age is in analytics. If you're running high call volumes and need custom exports or deep reporting beyond the dashboard you'll find the tooling thinner than the orchestration layer.
Key Features
- Omnichannel Agent Builder: No-code visual flow builder that deploys the same agent across voice, chat, and email from one configuration, with branching logic, variable extraction, and API tool calls.
- Model-agnostic routing lets you mix-and-match STT (Deepgram), TTS (ElevenLabs, Cartesia, Rime AI, Inworld AI), and LLM (GPT, Claude, Gemini, custom) per agent without rebuilding the pipeline.
- MCP Server: Exposes the voice AI stack as tools manageable directly from an IDE or MCP client, covering agents, calls, campaigns, webhooks, and phone numbers.
- BYOC telephony: Native SIP with Twilio and Telnyx integrations, plus custom SIP for teams with existing telephony infrastructure.
- The App Library includes ready-to-use integrations for Shopify, Zendesk, Gorgias, and other CRM and helpdesk tools, with real-time tool calling during live conversations.
Pros and Cons
Pros:
✅ Single backend manages all three channels with unified conversation memory and context across switches
✅ MCP server lets developers configure and manage agents directly from their IDE without leaving the codebase
✅ Consistently rated for setup speed and omnichannel reliability across independent reviews
Cons:
❌ Analytics exports and detailed reporting are thinner than what high-volume teams need at scale
❌ Documentation depth for advanced features lags behind the builder's capabilities, per user feedback
What Users Say
"What I really like about SigmaMind: The speed is legit. I was skeptical about the sub-800ms claim, but the conversations actually feel natural." — Ankur Pandey, G2
"I got emails from someone from Sigma that sound personalized. They even sent me follow-up emails. But then, when I replied with two questions and my own follow-up, nobody replied." — Verified User, Reddit
Pricing
Pay-as-you-go at $0.04/min for voice agents and $0.005/message for chat, billed monthly. There are no subscription or concurrency charges. There's also enterprise pricing with volume discounts on request.
Bottom Line
SigmaMind earns its place when the same agent needs to run across voice, chat, and email without rebuilding logic per channel. Voice-only teams that need deeper call analytics will find Retell AI or Telnyx a better match.
7. Rapida: Best for White-Label and Enterprise Voice AI Ownership
What it does: Rapida is an open-source voice AI for agent orchestration platform written in Go, built for agencies delivering white-label deployments and enterprise teams that need data sovereignty and full-stack ownership.
Best for: Agencies reselling voice AI under their own brand, enterprise teams with strict data residency requirements, and CPaaS/CCaaS operators who need multi-client isolation and zero platform markup on provider costs.
Running a multi-client deployment on Rapida's managed cloud, each client account lived in its own workspace with separate assistant configuration, telephony numbers, and call logs, all reachable from a single operator view.
Switching a client from managed cloud to a private VPC required no application code changes, just a deployment target swap.
The platform's main friction point isn't architecture, it's community. At 665 GitHub stars, Rapida's ecosystem is early compared to LiveKit or Pipecat, which means fewer third-party integrations and less peer-sourced troubleshooting outside the official Discord.
Key Features
- White-label workspaces: Client-isolated deployments with repeatable templates, brand-ready delivery, and reseller-friendly multi-account management from a single operator layer.
- Zero platform markup means provider costs (STT, TTS, LLM, telephony) pass through at cost with no Rapida margin layer. Self-hosted deployments add no licensing fee on top of infrastructure.
- AgentKit (custom gRPC backend): Plug any custom LLM server in over gRPC while Rapida manages the full audio pipeline, turn detection, and telephony.
- Session traces: Every call logs full transcripts, LLM requests and responses, latency breakdowns per pipeline stage, webhook delivery, and handoff records in a single timeline.
- Omnichannel from one config lets you deploy the same assistant to phone (SIP/PSTN), web widget, WebRTC app, and WhatsApp from a single configuration with no per-channel code duplication.
Pros and Cons
Pros:
✅ GPL-2.0 open-source codebase with managed cloud and self-hosted on the same APIs, SDKs, and configuration
✅ Provider-agnostic across every layer: 10+ LLMs, 10+ STT providers, 9 TTS providers, and any SIP-compatible carrier
✅ Multi-tenant architecture with reusable deployment templates and reseller-friendly account management baked into the platform from day one
Cons:
❌ Ecosystem is early compared to LiveKit and Pipecat, with fewer third-party integrations and community-sourced troubleshooting resources
❌ Enterprise plan pricing requires direct contact, with no public rate card for private or dedicated deployments
What Users Say

"For sure, but those stacks handle models. They don't handle the ugly stuff: telephony, streaming, state, retries, memory rollpver, context switch, handovers and reliability. That's what Rapida is for. Not slop infrastructure." — Verified User, Reddit
"There is a need for documentation for starting each localhost server. All the challenges that come and their resolutions." — Verified User, Github
Pricing
Launch plan is $0 with 1 agent, no credit card required, and community support. Scale runs $500/month with 4 agents, 100,000 audio session minutes, and up to 200 concurrent sessions.
Bottom Line
Rapida is built around agency white-label delivery, strict data residency, and enterprise procurement that requires an open-source codebase. Retell AI and VAPI are the faster starting points for teams without those constraints.
Which Voice AI Orchestration Tool Should You Choose?
Every platform on this list handles voice AI for agent orchestration. The differences that matter show up in who owns the infrastructure, how much of the stack you want to control, and what happens when you need to swap a model at 2 am.
Choose Cekura on top of any of these if:
- You want a test layer that runs the same simulation suite across whichever orchestrator you pick
- You need regression testing before every prompt or model swap
- You want production conversation monitoring with replay
Choose VAPI if you:
- Need to swap STT, LLM, or TTS providers independently without touching the rest of the pipeline
- Want to bring your own API keys and eliminate platform markup on model costs
- Have engineering capacity to tune a multi-vendor stack and don't mind tracking layered billing
Choose Retell AI if you:
- Need to ship a phone agent to production in under a day with HIPAA compliance included at no extra cost
- Run contact center or healthcare workflows where latency consistency under load matters more than provider choice
- Want a single platform fee without assembling separate telephony, STT, LLM, and TTS contracts
Choose LiveKit if you:
- Want full open-source control (Apache 2.0) with self-host or managed cloud on the same APIs
- Are building multimodal agents that combine voice, video, and data in the same session
- Have the engineering depth to own infrastructure and expect call volume high enough that self-hosting offsets the setup overhead
Choose Pipecat if you:
- Write Python and want frame-by-frame visibility into every stage of the STT-LLM-TTS pipeline
- Need to orchestrate 100+ provider combinations without locking into a platform's defaults
- Are comfortable designing the pipeline yourself and don't need a no-code builder
Choose Telnyx if you:
- Want a single vendor covering telephony, STT, TTS, LLM orchestration, and global numbers across 140+ countries
- Need STIR/SHAKEN A-level attestation so outbound calls display as trusted rather than spam
- Are building for global markets where carrier-grade call quality and regional PoPs reduce latency at the network layer
Choose SigmaMind if you:
- Need the same agent brain running across voice, chat, and email without rebuilding conversation logic per channel
- Want to configure and deploy agents directly from your IDE via MCP without switching to a dashboard
- Are building for mid-market or enterprise and need model-agnostic routing with SOC 2 Type II compliance on a pay-as-you-go plan
Choose Rapida if you:
- Are an agency that needs white-label client isolation, repeatable deployment templates, and zero platform markup on provider costs
- Have enterprise procurement requirements where open-source licensing and self-hosted data residency are non-negotiable
- Need to run the same stack across the managed cloud and private VPC without changing the application code
Skip this category entirely if:
- Your call volume is low enough that a bundled tool like a CRM's native dialer already covers the use case
- Your team has no Python, Go, or Node.js capacity and needs a fully no-code, no-infrastructure solution with zero developer involvement
Final Verdict
For teams that need to ship a phone agent fast without managing infrastructure, Retell AI is where this list starts. VAPI is the developer-first option when owning every provider choice is non-negotiable. If you need to own the infrastructure entirely, LiveKit and Pipecat are both strong options, with the choice depending on whether you want a Python-native framework or a WebRTC-first stack with multimodal support.
For carrier-grade telephony, omnichannel orchestration, or white-label delivery, Telnyx, SigmaMind, and Rapida each serve a distinct version of those requirements.
The comparison chart covers the parameters. A real call flow on one or two of these will tell you the rest.
How to Know Your Voice API Stack Performs Once It Goes Live
Every API on this list gives you a voice pipeline. However, none of them tells you whether your agent performs once a real caller is on the line. This means you usually find out something's wrong after the fact, when a caller drops or a transcript comes back wrong.
Cekura runs on top of whichever provider you choose and closes that gap.
Pre-production
- Automated simulations: Thousands of simulated calls run before go-live, catching the edge cases that only surface when real callers push your agent off-script.
- Regression testing: Every time you swap a TTS model, update a prompt, or change a voice provider, Cekura runs your full test suite before anything goes live.
- A/B testing: Compare multiple versions of your agent against the same call scenarios and review results in one place.
Infrastructure
- Interruption detection: When the agent talks over a caller or cuts off mid-sentence, Cekura flags those timing patterns in the test report.
- Latency tracking: Measures where slowdowns originate in the pipeline so you know exactly what to fix after each update.
Observability
- Production call QA: Monitors live calls for drop-off points, negative sentiment, and workflow adherence across volumes that manual review can't cover.
- Conversation replay: When something breaks in production, replay that exact exchange against your updated configuration to confirm the fix held.
- Custom evaluation: Score every call on accuracy, missed intents, and incorrect responses using your own criteria.
Native integrations work out of the box for Retell, VAPI, ElevenLabs, LiveKit, Pipecat, Bland, and more. You don't rebuild anything. You add a testing and monitoring layer on top of what you already have.
It's SOC 2-, HIPAA-, and GDPR-compliant for transcript redaction, role-based access, and audit trails.
Building on one of these APIs and want to know if your agent performs under real call volume? Schedule a demo with Cekura to see how it tests and monitors your stack in production.
Frequently Asked Questions
What Is the Best Voice AI Tool for Agent Orchestration in 2026?
Retell AI leads on deployment speed, with managed full-stack deployment, ~600ms latency, and HIPAA compliance starting at $0.07/min with 20 concurrent calls included. VAPI pulls ahead when provider flexibility matters more than deployment speed.
What Is Voice AI for Agent Orchestration?
Voice AI agent orchestration is the real-time coordination of STT, LLM, and TTS into a single pipeline that handles turn detection, interruptions, and tool calls during a live call. The layer determines when the agent speaks, when it listens, and when to hand off to a human.
How Much Does Voice AI for Agent Orchestration Cost per Minute?
Voice AI for agent orchestration costs between $0.04 and $0.07 per minute in platform fees, with STT, LLM, and TTS costs added on top, where billing is modular. Rapida starts free and scales to $500/month on managed cloud, with no platform markup on provider costs at any tier.
What Is the Difference Between VAPI and Retell AI for Voice Agent Orchestration?
The main difference between VAPI and Retell AI is stack ownership. VAPI lets you bring your own providers and pay model costs at cost with no markup. Retell AI bundles the full pipeline, including telephony and HIPAA compliance at $0.07/min.
Does Voice AI for Agent Orchestration Require Coding Experience?
No, not always. Retell AI, SigmaMind, and Telnyx offer no-code builders for non-developers. VAPI, LiveKit, Pipecat, and Rapida require engineering capacity to configure pipelines and manage infrastructure.