
Most voice AI failures don't happen because of hallucinations or mispronunciations.
They happen during silence.
A caller pauses briefly to check information. The agent assumes the turn is over and interrupts. Or the caller finishes speaking and hears nothing. Two seconds later:
"Hello? Are you there?"
The agent responds, talking over them.
These breakdowns feel minor, but they are the primary cause of call frustration and abandonment in production voice systems.
At Cekura, we learned that scaling voice AI reliably isn't about smarter models, it's about mastering the milliseconds between words.
This post breaks down how we improved production reliability for conversational voice agents built on Pipecat, and what engineering teams must consider when deploying voice AI at scale.
Why Voice AI Breaks in Production
In staging environments with clean audio and stable networks, voice agents perform well. Production is different.
Real traffic introduces:
- Network jitter
- Provider latency spikes
- Background noise
- Unpredictable speaking styles
- Transcript failures
- High concurrency loads
Under these conditions, voice systems often stall, interrupt users, or overlap turns.
We observed three recurring failure modes.
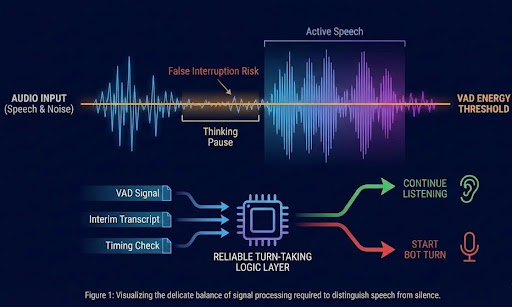
Failure Mode 1: VAD Is Not Turn Detection
Most systems use energy-based Voice Activity Detection (VAD) to detect when users stop speaking.
The problem: speech is not continuous.
Users pause to think. They hesitate. They change direction mid-sentence.
Energy-based VAD cannot distinguish between:
- A thinking pause
- End-of-turn silence
Result:
- Agents interrupt users mid-sentence
- Conversations feel unnatural and rushed
VAD alone cannot reliably drive conversational turn-taking.
Failure Mode 2: Latency Spikes Kill Conversations
Voice conversations have strict latency budgets.
Typical expectations:
- Agent response perceived as instant: <300 ms
- Noticeable delay: >700 ms
- Conversation feels broken: >1500 ms
In practice, LLM and TTS providers occasionally spike under load:
Normal TTFB: 200–300 ms
Peak-hour TTFB: 1500–2500 ms
A two-second silence feels like system failure to callers.
Agents stall even though providers eventually respond.
Failure Mode 3: Transcript Desynchronization
Speech-to-text pipelines degrade under:
- Noisy environments
- Packet loss
- Low-quality microphones
- Multiple speakers
Consequences include:
- Late transcript arrival
- Incorrect transcript segmentation
- Missing transcripts entirely
Once the transcript state diverges from the audio state, agents produce overlapping turns or dead air.
Conversation flow collapses.
Engineering for Resilience Instead of Accuracy
Fixing isolated components is insufficient. Production systems need architectural resilience.
We extended Pipecat with reliability mechanisms that allow agents to predict and recover from failures rather than simply reacting to them.
Reliable Turn-Taking Beyond VAD
We implemented a multi-signal turn controller combining:
- VAD signals
- Interim transcript updates
- Timing thresholds
- Conversation state validation
The decision logic answers:
- Is the user pausing or done speaking?
- Should agent speech be interrupted?
- Should a new turn begin?
Timeouts adapt based on speech cadence, preventing premature interruptions while keeping agents responsive.
This dramatically reduces barge-in errors and turn overlap.
Pre-Emptive Provider Fallbacks
Most voice stacks assume providers will respond eventually.
But production systems cannot wait.
We implemented latency-aware service switching:
Runtime logic
- Monitor TTFB for every request.
- Enforce strict latency budgets.
- Switch providers before user-perceived delay occurs.
Example:
Primary LLM: Gemini
Fallback: Azure OpenAI
Primary TTS: ElevenLabs
Fallback: Cartesia
If response latency exceeds the threshold, requests are immediately rerouted.
The caller experiences continuous conversation with no visible interruption.
Fallbacks become invisible reliability layers.
Decoupling Conversation Turns from Audio Streams
Traditional systems bind conversational state to audio flow.
We decoupled:
- Audio streaming
- Turn management
- Transcript processing
- LLM responses
- TTS playback
This enables:
- Controlled interruptions
- Graceful handling of silence
- Recovery from transcript loss
- Telephony edge-case handling
It also enables robust testing under failure conditions.
Testing Reliability with Evaluator Agents
Resilience cannot be assumed. It must be tested.
We simulate real-world stress using evaluator personalities:
Stress scenarios
- High interruption users
- Slow speakers with long pauses
- Noisy environments
- Packet loss and jitter injection
- Non-verbal reactions (laughs, coughs)
Thousands of simulated calls validate that agents maintain conversational flow even when networks and providers degrade.
Production reliability requires adversarial testing.
Continuous Production Guardrails
Resilience requires constant vigilance. We have set up custom metrics on our production call monitoring, tracking the silence between turns and identifying if any interruptions are happening, so we can catch latency patterns before they impact users. This creates a real-time feedback loop, allowing us to fine-tune timeouts and fallback triggers based on live performance data rather than just lab simulations.
Key Lessons for Voice AI Engineers
Teams deploying conversational agents should assume:
- VAD alone is insufficient for turn detection.
- Providers will spike or fail under load.
- Transcripts will desynchronize.
- Silence handling determines perceived intelligence.
- Latency resilience matters more than model quality.
Production voice AI is fundamentally a distributed systems problem.
Reliability is the Real Product Feature
Users don't judge voice AI by correctness alone.
They judge by flow.
If conversations feel natural, users trust the system. If silence appears or interruptions occur, trust disappears instantly.
Reliability, not just intelligence, is what separates production voice AI from demos.
Test Your Agent Under Real Conditions
Cekura helps teams test, simulate, and monitor conversational AI in production.
Try it yourself:
Start free trial: https://dashboard.cekura.ai/overview
Book demo: https://www.cekura.ai/expert