
Whenever a new LLM launches—be it DeepSeek, Gemini 2.5 Flash, or GPT-5 — we see a wave of excitement in the Conversational AI community. Customers often ask us on demo calls:
Should we move our Voice AI or Chat AI agents to the latest model?
The answer isn’t as simple as chasing the newest release. Each LLM brings unique tradeoffs that must be carefully evaluated through testing, benchmarking, and observability.
Why Choosing the Right LLM Matters in Conversational AI
For Voice AI and Chat AI, model performance is rarely one-size-fits-all. The right choice depends on:
- Latency requirements (critical in real-time TTS/STT for voice agents)
- Instruction following & tool calls (some models regress here)
- Cost sensitivity at scale
- Prompt adaptability (older prompts often fail without re-tuning)
For example, when some of our customers moved from GPT-4o to Gemini, costs and overall conversational quality improved, but tool calls fared poorly — a reminder that every LLM change comes with tradeoffs.
This is why systematic evaluation, simulation, and QA pipelines are essential before any migration.
Our A/B Test: GPT-5 vs GPT-4o
At Cekura (YC F24), we ran a controlled A/B testing and benchmarking exercise comparing GPT-5 with GPT-4o, the current gold standard for voice agents.
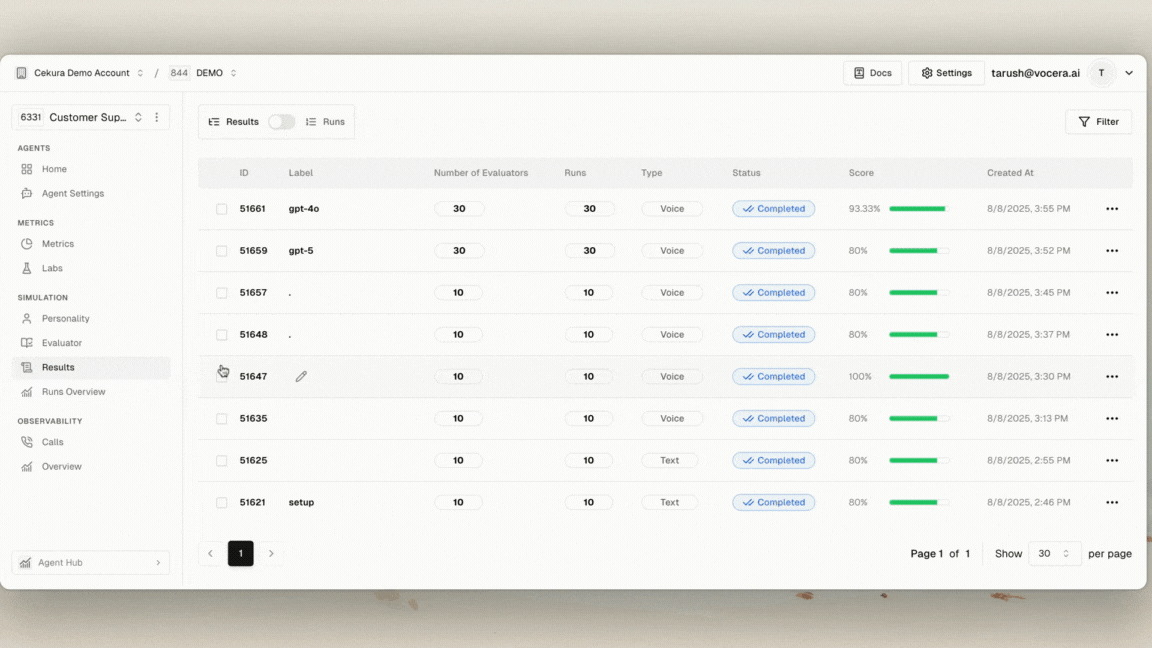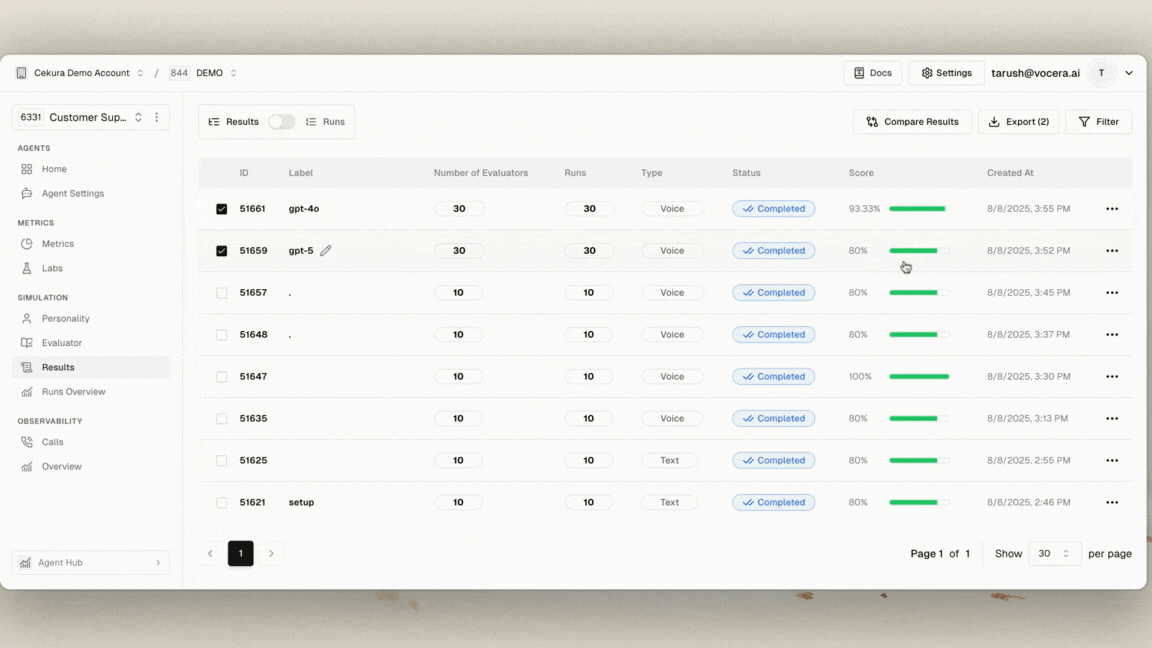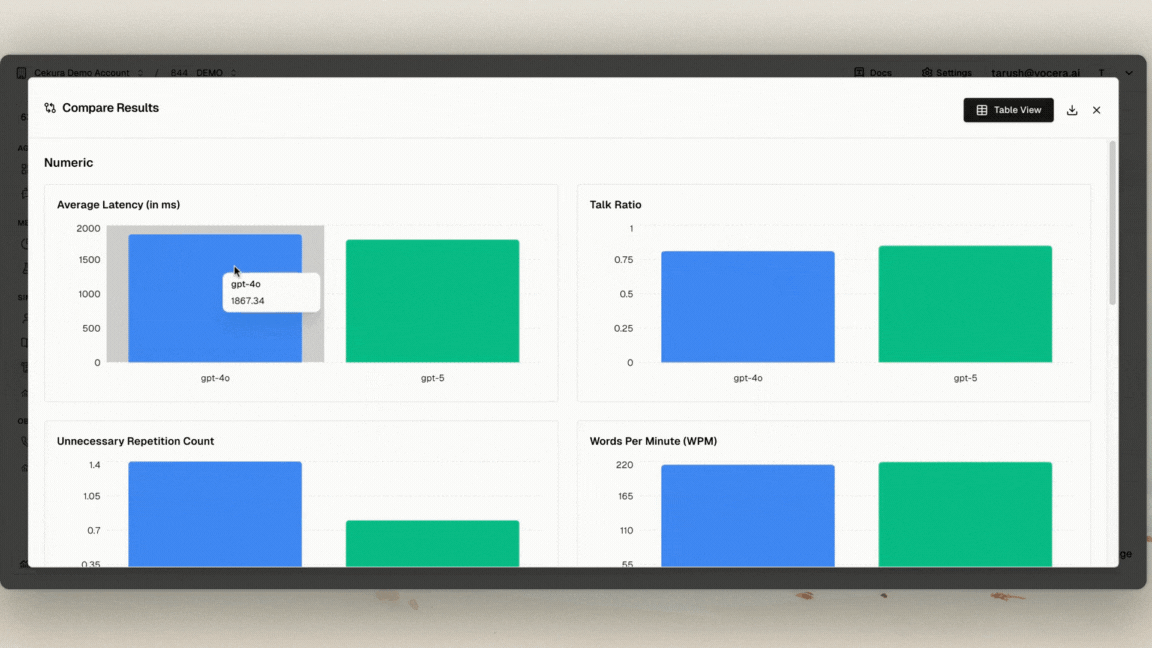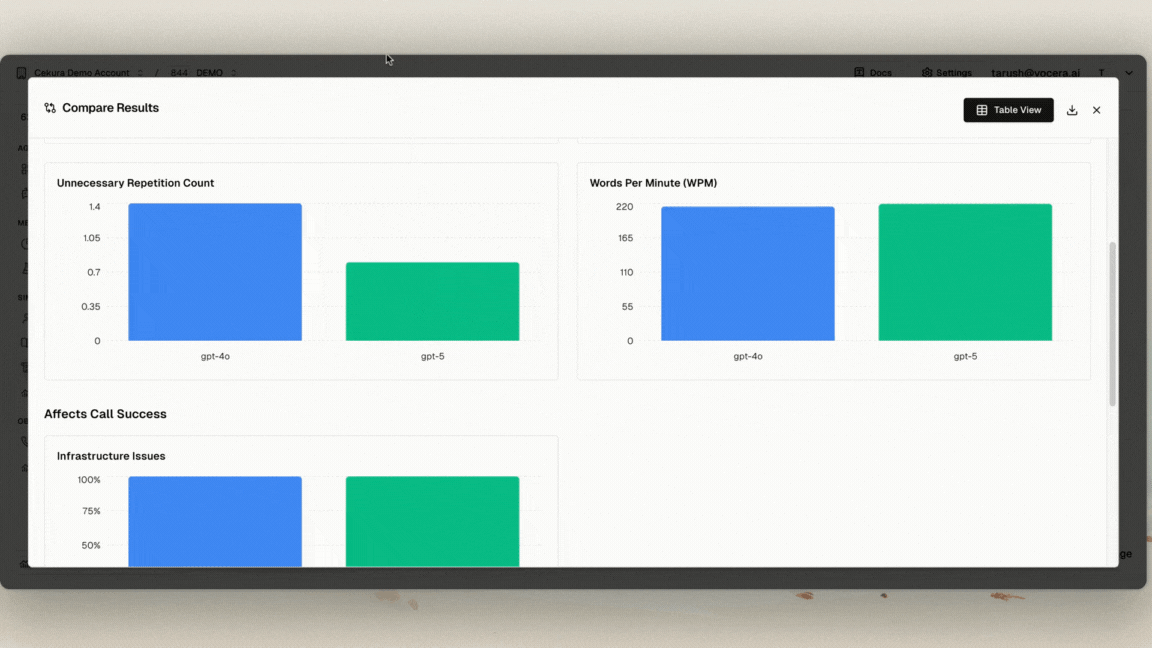
- 🔻 Regression Testing revealed accuracy loss – Out-of-the-box, GPT-5 scored 80% vs GPT-4o’s 93.33%. Old prompts simply don’t transfer.
- 🟢 Repetition reduced by 50% – More natural and less robotic conversations.
- 🟢 Consistency improved by 6.6% – Better instruction-following across sessions.
The lesson: Switching models without testing is risky. You must re-engineer prompts and validate across multiple conversational scenarios.
How to Evaluate a New Model Before Migration
Adopting a new LLM requires the same rigor as any software release. We recommend setting up an LLM CI/CD pipeline that includes:
- Simulation & Testing: Run conversational scenarios covering tool calls, context retention, and dialogue flow.
- Regression Testing: Ensure the new model doesn’t break existing use cases.
- Stress Testing & Load Testing: Validate how the model performs under heavy concurrency in Voice AI or Chat AI environments.
- Red Teaming: Actively probe for failure modes, hallucinations, or policy gaps.
- Monitoring & Observability: Track latency, interruptions, and costs in production.
This approach helps you benchmark tradeoffs in QA fashion—before customers experience them.
Final Takeaway
Every new LLM—whether GPT-5, Gemini, or DeepSeek, is not an instant upgrade. It’s a new component that must be evaluated, tested, and validated against your use case.
To succeed, enterprises need:
- Robust A/B testing and benchmarking pipelines
- Continuous QA, regression testing, and monitoring
- A clear framework for cost, latency, and conversational quality tradeoffs
The future of Voice AI and Chat AI won’t be about picking the “best” LLM. It will be about building resilient testing and observability pipelines that allow you to evolve intelligently with every model release.
Schedule a demo to find out how you can A/B test your prompts, LLM, STT, and TTS with Cekura